LLM Performance Series: Batching
Starting from the September Trustbit LLM Benchmark we put special emphasis on the enterprise workloads. These include types of LLM tasks that are common to business digitalisation at scale:
generation of marketing texts that present a specific product to a given audience within JTBD framework;
information retrieval and Q&A systems;
CRM automation;
automated lead generation.
While many customers are happy with using ChatGPT from OpenAI or Microsoft Azure, some are still interested in running models locally, completely under their control. This is what the benchmarks are for! They help to track improvement of SOTA (State of the Art) models and pick the best ones for the task at hand.
While cloud models are usually managed (pay-as-you-go), running models locally requires a different investment scheme. Companies either rent GPUs per hour or buy them and install into their own servers.
Either of these options involves a different type of investment. It will also come with different Return on Investment.
GPUs aren’t exactly cheap or easy to get these days. So we want our customers to make the best use of their investments.
The means that while evaluating models for different projects, we need to take into the account not only their accuracy on the specific tasks, but also performance and cost. To help with that we have added corresponding columns: cost and speed:
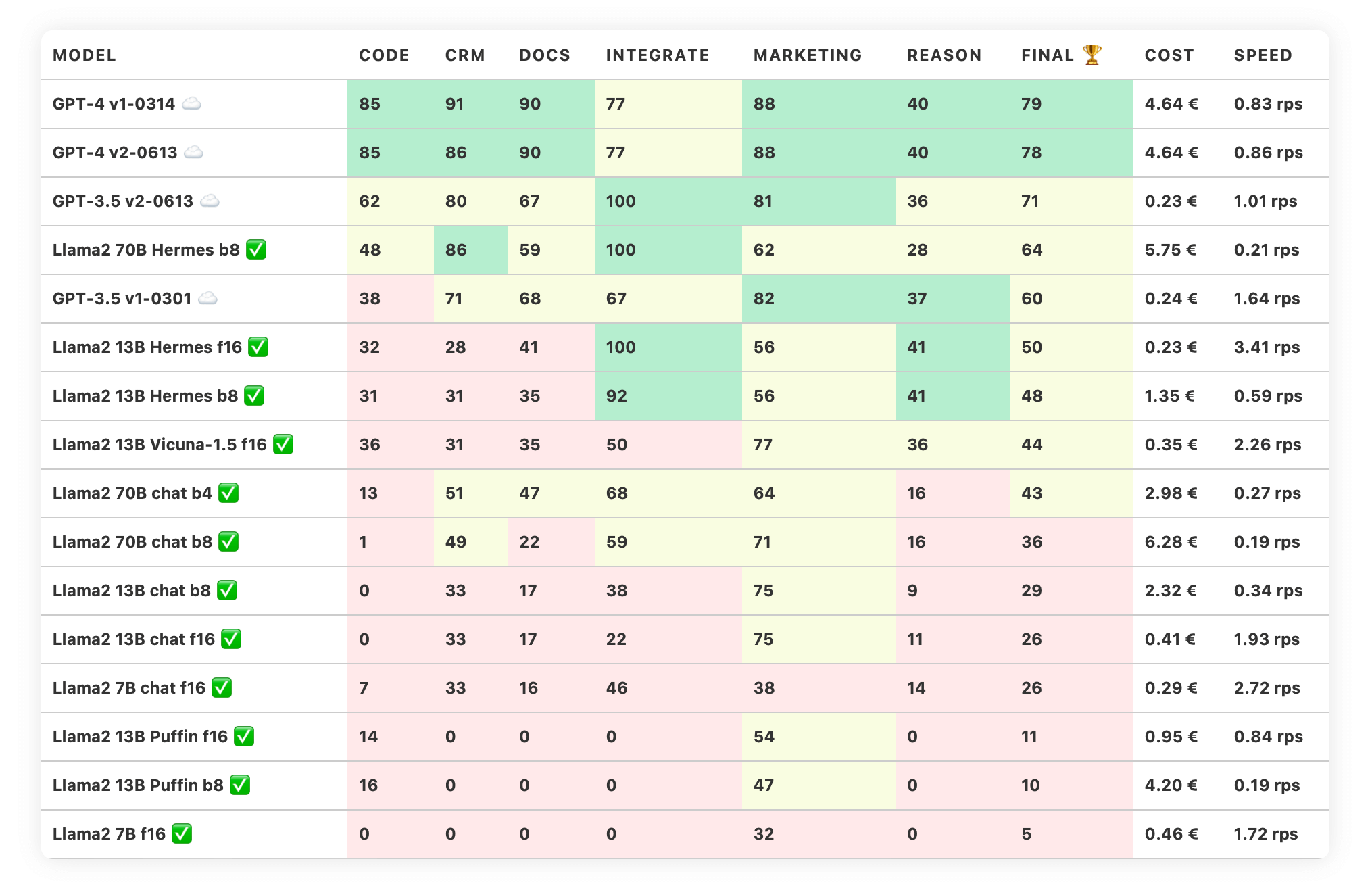
Trustbit LLM Leaderboard, September 2023
Cost is a relative number that estimates “how much money would it cost to run the entire benchmark on this configuration”. Since our benchmarks represent a mix from the real business workloads, costs should help to compare different models.
For the SaaS models (like OpenAI) we use price per token (prompt + completion). For the local models we estimate, how much would it take to rent a sufficiently large GPU from a major cloud vendor for the duration of the benchmark.
Speed represents number of requests per second that we can get from a model while running benchmarks in a single-inference mode (batch_size of 1).
But can we get better results? Indeed, there is a number of performance optimisations that could further boost performance and even quality of these models. The first one is batching.
Performance optimisation: batching
GPU batching is based on the fact that GPU is a very special piece of hardware. In certain cases, it doesn’t care much, if it needs to process 1 request or 10, as long as there is enough memory. Computations will roughly take the same amount of time.
In other words, if we have 10 requests, we could run them on the same GPU roughly in the same amount of time.
To illustrate the concept, we took a recently released LLama2 model - Nous Hermes 13B. It is open for the commercial use and strikes a good balance between accuracy and cost.
The workload involved to generating 20 more tokens in a text completion. The model was run on Nvidia A100 80GB PCIe using HuggingFace transformers library. We tested batch sizes from 4 to 400 with step of 4. Here are the results:

As you can see, adding more requests doesn’t result in a proportional increase of the processing time. This leads to ever growing throughput, measured tokens per second (TPS), until the number hits the ceiling around 2500 tokens per second.
If we stayed at batch size of 1, we would’ve never made it past 200 tokens per second.
Note: GPU memory consumption jumps back and forth because it is gets released only when there is a memory pressure. You can watch lower peaks to see the absolute minimal consumption.
Doesn’t this mean that the highest batch size is absolutely the best? Not necessarily. So far we have fixed a number of tokens for LLM to generate at 20. In some tasks, like generation of marketing texts, we would like to get more.
As we generate longer texts, GPU memory requirements tend to grow, while the speed decreases. This comes from the fact that after we generated one token, we need to pass the entire text back to the model for generating the next one. Rinse and repeat.
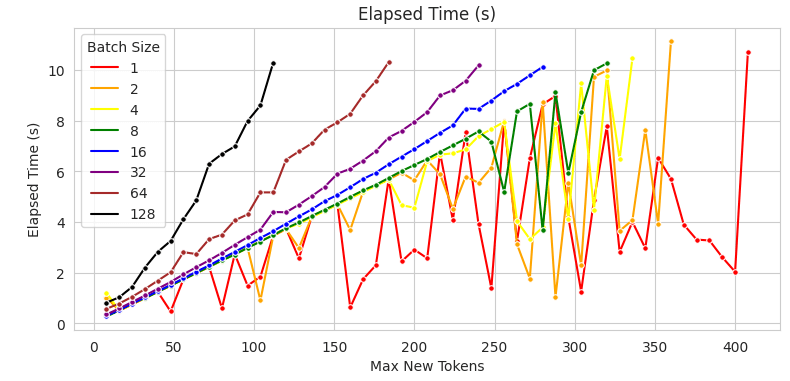
Let’s see how our generation capabilities change, as we prompt LLM model for more tokens.
The chart below shows that prompting for more tokens increases computation time. However, we can lower that time a bit by making our batch sizes smaller:
How does this translate into efficiency of the models? Here is another chart that compares throughput (tokens per second) of the same experiments:

Best throughput comes with a large batch size. However, as the completion length increases (more iterations are required), we need to lower our batch size in order to stay within 10 second time budget for the entire completion.
Depending on the expected prompt length in our solutions, we could optimise for the highest throughput and lowest latency, leading to a better customer satisfaction and better ROI. Charts like the one above help with such tasks.
But can we get better performance? There are still many other knobs to tune, for example: quantisation, speculative execution, using different inference runtimes. Each comes with its own trade-offs. Stay tuned!