September 2023
Benchmarks für ChatGPT & Co:


Jeden Monat neu: Das Trustbit LLM Leaderboard ist eine monatlich aktualisierte Gegenüberstellung unterschiedlicher Large Language Models wie ChatGPT und weitere zur Verfügung, um deren Anwendbarkeit in der Produktentwicklung zu bewerten.
Trustbit Leaderboard September 2023
Die Trustbit-Benchmarks bewerten die Modelle in Bezug auf ihre Eignung für die digitale Produktentwicklung. Je höher die Punktezahl, desto besser.
Wir unterscheiden zwischen proprietären Cloud-Modellen und Open-Source-Modellen mit großzügigen Lizenzen:
☁️ Kennzeichnet Cloud-Modelle (proprietary)
✅ Kennzeichnet Open-Source-Modelle, die lokal ausgeführt werden können.
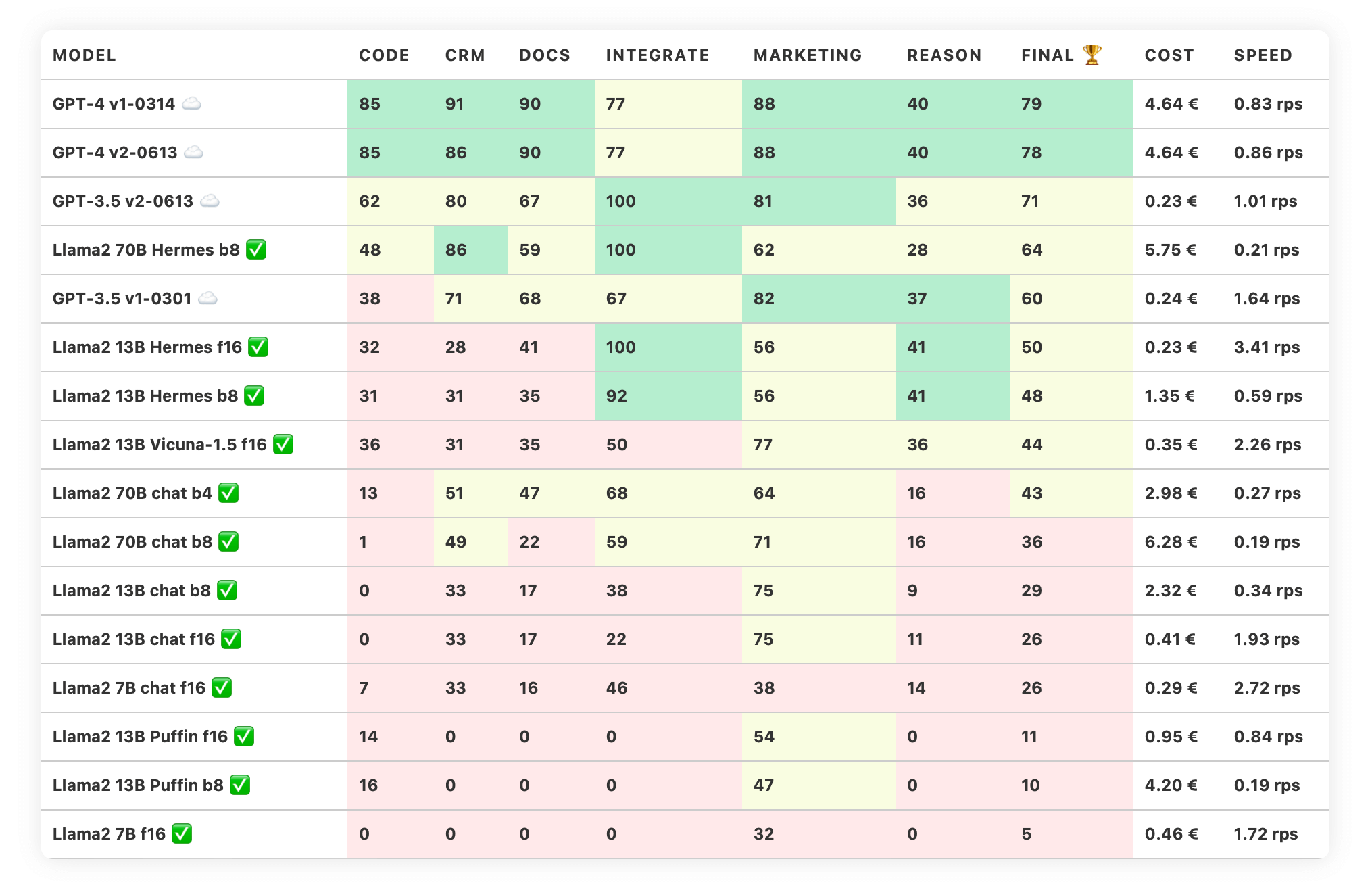
Die Spalte "Cost" zeigt die geschätzten Kosten für die Ausführung der Arbeitslast an. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Eine höhere Geschwindigkeit ist besser.
Auf strategischer Ebene verbessert sich die GPT/LLM-Landschaft von Monat zu Monat. Wir erwarten, ab 2024 einige Projekte von Cloud-Diensten auf lokale Modelle umstellen zu können.
Bemerkenswerte Verbesserungen sind:
Die Veröffentlichung von Llama 2 durch Meta, die eine weitere Innovationsrunde durch ihre großzügige Lizenz anregt.
Die Veröffentlichungen von Code Llama und dem sprachunabhängigen Modell "Sonar". Diese sind in diesem Benchmark nicht enthalten, ergänzen jedoch generische LLMs. Sie funktionieren besonders gut mit unternehmensspezifischen Assistenzsystemen für bestimmte Fachbereiche.
Überraschende Ergebnisse beim Benchmarking von Llama2 und Nous Hermes 70B
Beim Benchmarking neuer vielversprechender Modelle stellte sich überraschenderweise heraus, dass Llama2 selbst nicht besonders gut geeignet ist, um LLM-gesteuerte Produkte zu entwickeln. Es ist zu gesprächig. Es gibt jedoch offene Feinabstimmungen von Llama2, die besonders gut funktionieren, insbesondere Nous Hermes 70B. Dies ist das erste offene Modell, das ChatGPT 3.5 in unseren Benchmarks geschlagen hat.
Kosten und Qualität: Das 70B-Modell im Vergleich
Dieses 70B-Modell kann etwas teuer im Betrieb sein. Das Ausführen einer Arbeitslast, die diesem Benchmark entspricht, kostet etwa ~5,75 EUR auf einer von einem großen Cloud-Anbieter gemieteten GPU-Maschine. Dies ist jedoch erst der Anfang des größeren Trends zur Verbesserung der Qualität zu erschwinglichen Kosten. Die 13B-Feinabstimmungen von Llama 2 holen auf, während das neue Falcon 180B-Modell Druck auf die Spitze ausübt.
Darüber hinaus sind weniger leistungsfähige Modelle immer noch einen Blick wert, insbesondere wenn wir neue Formen von Guidance und der domänenspezifischen Beam-Suche entdecken und einsetzen.
Trustbit LLM Benchmarks Archiv

Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!