Benchmarks für ChatGPT und Co
Mai 2024

Highlights der neuesten Modelle
Neue Google Gemini 1.5 Version - besser als die vorherigen
GPT-4o - das Beste in diesem Benchmark, aber mit Einschränkungen
Qwen1.5 Chat - eines der besten downloadbaren Modelle
IBM Granite Code Instruct - gute Ergebnisse beim Coding mit sauberer Datenbasis
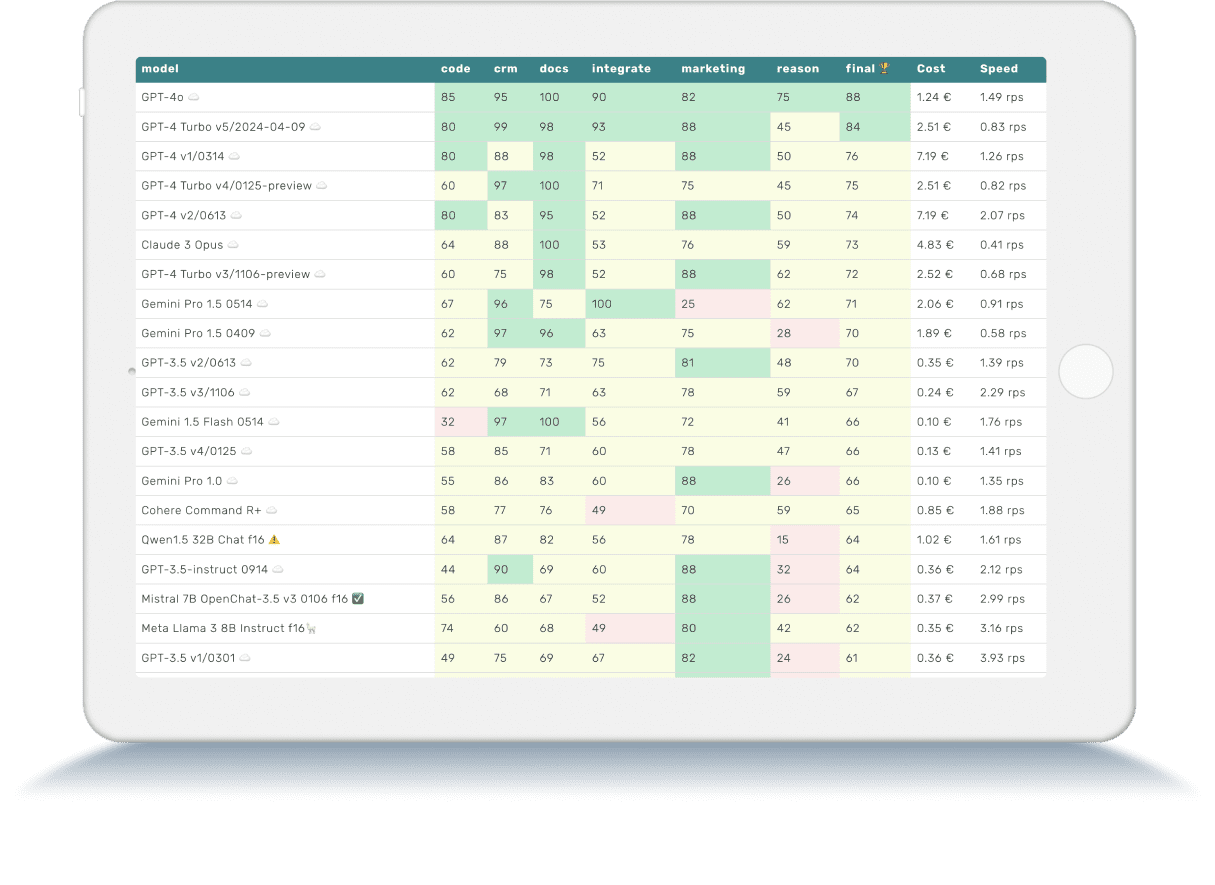
LLM Benchmarks | Mai 2024
Die Trustbit-Benchmarks bewerten die Modelle in Bezug auf ihre Eignung für die digitale Produktentwicklung. Je höher die Punktezahl, desto besser.
☁️ - Cloud-Modelle mit proprietärer Lizenz
✅ - Open-Source-Modelle, die lokal ohne Einschränkungen ausgeführt werden können
🦙 - Lokale Modelle mit Llama2-Lizenz
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4o ☁️ | 85 | 95 | 100 | 90 | 82 | 75 | 88 | 1.24 € | 1.49 rps |
| GPT-4 Turbo v5/2024-04-09 ☁️ | 80 | 99 | 98 | 93 | 88 | 45 | 84 | 2.51 € | 0.83 rps |
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| Claude 3 Opus ☁️ | 64 | 88 | 100 | 53 | 76 | 59 | 73 | 4.83 € | 0.41 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| Gemini Pro 1.5 0514 ☁️ | 67 | 96 | 75 | 100 | 25 | 62 | 71 | 2.06 € | 0.91 rps |
| Gemini Pro 1.5 0409 ☁️ | 62 | 97 | 96 | 63 | 75 | 28 | 70 | 1.89 € | 0.58 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| Gemini 1.5 Flash 0514 ☁️ | 32 | 97 | 100 | 56 | 72 | 41 | 66 | 0.10 € | 1.76 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| Gemini Pro 1.0 ☁️ | 55 | 86 | 83 | 60 | 88 | 26 | 66 | 0.10 € | 1.35 rps |
| Cohere Command R+ ☁️ | 58 | 77 | 76 | 49 | 70 | 59 | 65 | 0.85 € | 1.88 rps |
| Qwen1.5 32B Chat f16 ⚠️ | 64 | 87 | 82 | 56 | 78 | 15 | 64 | 1.02 € | 1.61 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| Meta Llama 3 8B Instruct f16🦙 | 74 | 60 | 68 | 49 | 80 | 42 | 62 | 0.35 € | 3.16 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 52 | 88 | 36 | 60 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Claude 3 Haiku ☁️ | 59 | 69 | 64 | 55 | 75 | 33 | 59 | 0.08 € | 0.53 rps |
| Mixtral 8x22B API (Instruct) ☁️ | 47 | 62 | 62 | 94 | 75 | 7 | 58 | 0.18 € | 3.01 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Claude 3 Sonnet ☁️ | 67 | 41 | 74 | 52 | 78 | 30 | 57 | 0.97 € | 0.85 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 45 | 84 | 35 | 55 | 2.24 € | 0.40 rps |
| Cohere Command R ☁️ | 39 | 63 | 57 | 55 | 84 | 26 | 54 | 0.13 € | 2.47 rps |
| Qwen1.5 7B Chat f16 ⚠️ | 51 | 81 | 60 | 34 | 60 | 36 | 54 | 0.30 € | 3.62 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 60 | 75 | 33 | 53 | 2.31 € | 0.35 rps |
| Qwen1.5 14B Chat f16 ⚠️ | 44 | 58 | 51 | 49 | 84 | 17 | 51 | 0.38 € | 2.90 rps |
| Meta Llama 3 70B Instruct b8🦙 | 46 | 72 | 53 | 29 | 82 | 18 | 50 | 7.32 € | 0.22 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
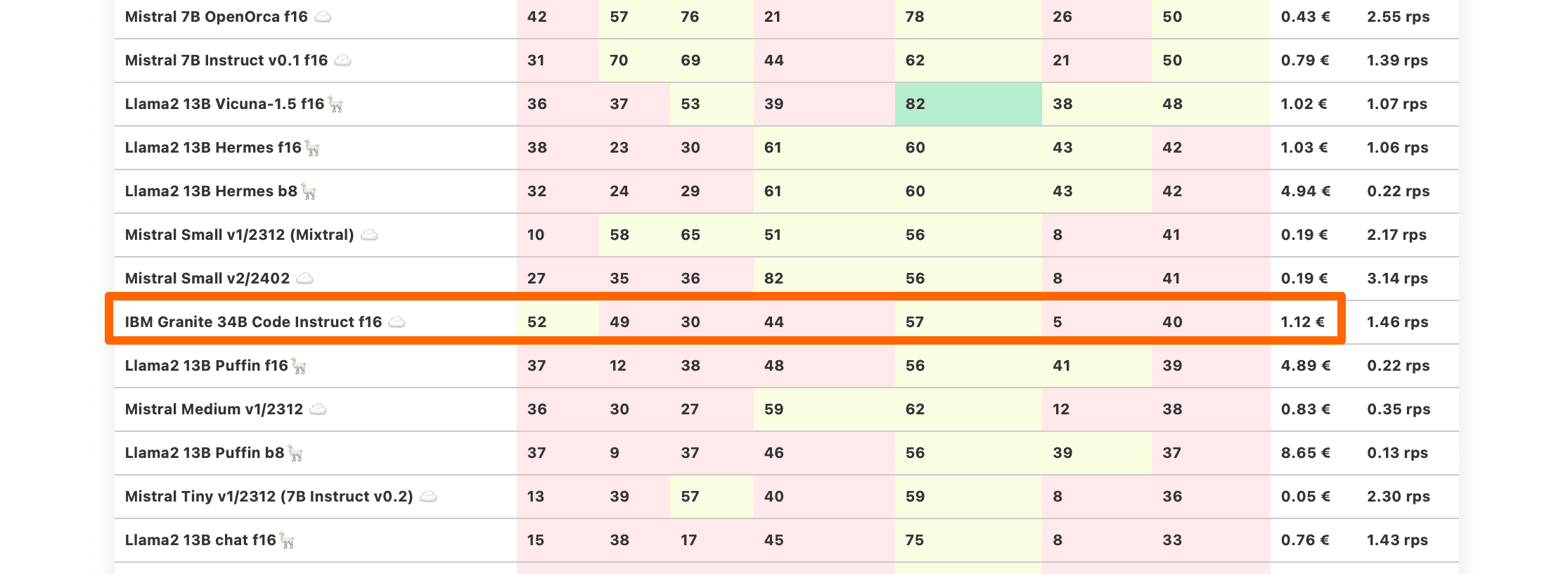
| IBM Granite 34B Code Instruct f16 ☁️ | 52 | 49 | 30 | 44 | 57 | 5 | 40 | 1.12 € | 1.46 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 48 | 56 | 41 | 39 | 4.89 € | 0.22 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 46 | 56 | 39 | 37 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 40 | 59 | 8 | 36 | 0.05 € | 2.30 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 45 | 75 | 8 | 33 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 45 | 75 | 6 | 32 | 3.35 € | 0.33 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 42 | 50 | 20 | 31 | 0.59 € | 1.86 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Microsoft Phi 3 Mini 4K Instruct f16 ⚠️ | 36 | 24 | 26 | 17 | 50 | 8 | 27 | 0.95 € | 1.15 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 3 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
Die Benchmark-Kategorien im Detail
Hier erfahren Sie, was wir mit den unterschiedlichen Kategorien der LLM Leaderboards genau untersuchen
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
-
Die geschätzten Kosten für die Ausführung der Arbeitslast. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
-
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Je höher die Geschwindigkeit, desto besser.
Google Gemini 1.5 - Pro and Flash
Die vor kurzem veröffentlichte Ankündigung von Google IO drehte sich ganz um die KI und Gemini Pro. Obwohl Google offenbar auf Gemini Ultra vergessen hat (es sollte Anfang dieses Jahres herauskommen), haben sie einige Modelle aktualisiert.
Gemini Pro 1.5 0514: Veränderte Stärken
Gemini Pro 1.5 0514 tauscht einige Dokumentenverständnisfähigkeiten zugunsten eines besseren logischen Denkens aus. Es stellt sich als eine etwas bessere Version als die vorherige Gemini Pro-Version heraus.
In unserer Erfahrung war es zu diesem Zeitpunkt auch etwas fehlerhaft. Wir haben eine Reihe von Serverfehlern erlebt und es sogar geschafft, eine „HARM_CATEGORY_DANGEROUS_CONTENT“-Flag zu erhalten.
Exzellente “Integrate” Fähigkeiten
Gemini Pro 1.5 erzielte eine perfekte „Integrate“-Punktzahl, bei der wir die Fähigkeit des LLM messen, Anweisungen zuverlässig zu befolgen und mit externen Systemen, Plugins und Datenformaten zu arbeiten.
Gemini 1.5 Flash als interessante Alternative zu GPT-3.5
Gemini 1.5 Flash ist eine interessante neue Ergänzung der Familie. Es funktioniert gut bei Dokumentenaufgaben und hat eine angemessene logische Denkfähigkeit. Kombiniert man das mit einem sehr niedrigen Preis, erhält man eine gute Alternative zu GPT-3.5.
Beachten Sie nur das eigenartige Pricing-Modell von Google Gemini - sie berechnen den Text nicht nach Tokens, sondern nach verrechenbaren Symbolen (Unicode-Codepunkte minus Leerzeichen). Wir haben gesehen, dass mehrere Entwickler:innen und sogar SaaS-Systeme Fehler bei der Kostenschätzung gemacht haben.

GPT-4o - Klar an der Spitze, aber mit einem Vorbehalt
GPT-4o sieht auf den ersten Blick perfekt aus. Es ist schneller und günstiger als GPT-4 Turbo. Es hat auch einen Kontext von 128K, erzielt höhere Punktzahlen, hat native Multimodalität und versteht Sprachen besser.
Zusätzlich hat es einen neuen Tokenisierer mit einem größeren Wörterbuch. Dies führt zu reduzierten Token-Anzahlen.

Insgesamt sind die Modellbewertungen nicht viel höher gestiegen, da wir bereits an der Grenze des Trustbit LLM Benchmarks arbeiten.
Es gibt nur einen Haken: Unsere Kategorie "Reason" (Fähigkeit der Modelle, komplexe logische und Denkaufgaben zu bewältigen) wurde von Natur aus schwierig gestaltet. GPT-4o schaffte es, die Punktzahl von 62 (GPT-4 Turbo v3/1106-preview) auf 75 zu erhöhen.
Was ist der Vorbehalt?
Sie sehen, OpenAI scheint in Zyklen zu arbeiten. Sie wechseln zwischen: „Lasst uns ein besseres Modell machen“ und „Lasst uns ein günstigeres Modell machen, ohne zu viel Qualität einzubüßen“.
Obwohl die LLM-Benchmarks es nicht erfassen, fühlt es sich an, als gehöre das GPT-4o-Modell zu den Kostenreduktions-Modellen. Es funktioniert erstaunlich gut bei kleinen Eingaben, jedoch zeigen andere Benchmarks, dass es nicht so gut mit größeren Kontexten umgehen kann wie die anderen GPT-4-Modelle. Es scheint auch an logischem Denken zu mangeln, obwohl aktuelle Benchmarks diese Regression nicht erfassen können.
💡 Derzeit ist das GPT-4 Turbo v5/2024-04-09 unser empfohlenes Standardmodell.
Qwen 1.5 Chat
Hohe Nachfrage und LMSYS Arena Bewertungen
Aufgrund der hohen Nachfrage und der guten Bewertungen in der LMSYS Arena haben wir uns entschieden, einige Varianten des Qwen Chat-Modells von Alibaba Cloud zu benchmarken.
Bewertung von Qwen 1.5 32B Chat
Qwen 1.5 32B Chat ist im Allgemeinen ziemlich gut. Es liegt im Bereich der GPT-3.5-Modelle und Gemini Pro 1.0. Es kommt jedoch mit einer nicht standardmäßigen Lizenz.

Wir haben auch Qwen 1.5 7B und 14B getestet - auch sie sind für ihre relative Größe ziemlich gut. Nichts Besonderes, aber dennoch eine anständige Leistung.

Die Lizenz von Qwen1.5 Chat ist das chinesische Äquivalent zu Llama 3: Sie können es frei für kommerzielle Zwecke verwenden, wenn Sie weniger als 100 Millionen MAU (Monatlich Aktive Nutzer) haben. Dies könnte die Einführung des Modells in den USA und der EU erschweren.
IBM Granite 34B Code Instruct
IBM Granite-Modelle sind eine besondere Art von Modellen. IBM geht weiter als viele andere, um Modelle mit klaren und transparenten Datenquellen zu trainieren.
Das ist jedoch das einzige Besondere an ihren Modellen. Während die vorherigen Versionen der IBM Granite-Modelle nur innerhalb der IBM Cloud verfügbar waren, wurde das getestete Modell direkt auf Hugging Face veröffentlicht.
Kurz gesagt, IBM Granite 34B Code Instruct hat eine anständige Fähigkeit zur Erzeugung von Code (für ein 7B-Modell) und schlechte Ergebnisse in fast allen anderen Bereichen. Wenn Sie ein lokales Modell mit einem Bruchteil der Rechenleistung suchen, dass Ihnen bei Programmieraufgaben hilft, wählen Sie besser Llama3 oder eines seiner Derivate.

Trustbit LLM Benchmarks Archiv
Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!