
Benchmarks für ChatGPT und Co
Januar 2024
Die Highlights des Monats:
Mistral 7B OpenChat v3 (0106) schlägt endlich ChatGPT-3.5 v1
Warum wir Mixtral 8x7B und Mistral-Medium nicht in den Benchmark aufgenommen haben
Ihre Ideen sind gefragt! Welche Aufgaben würden Sie gerne in unseren Benchmarks sehen?
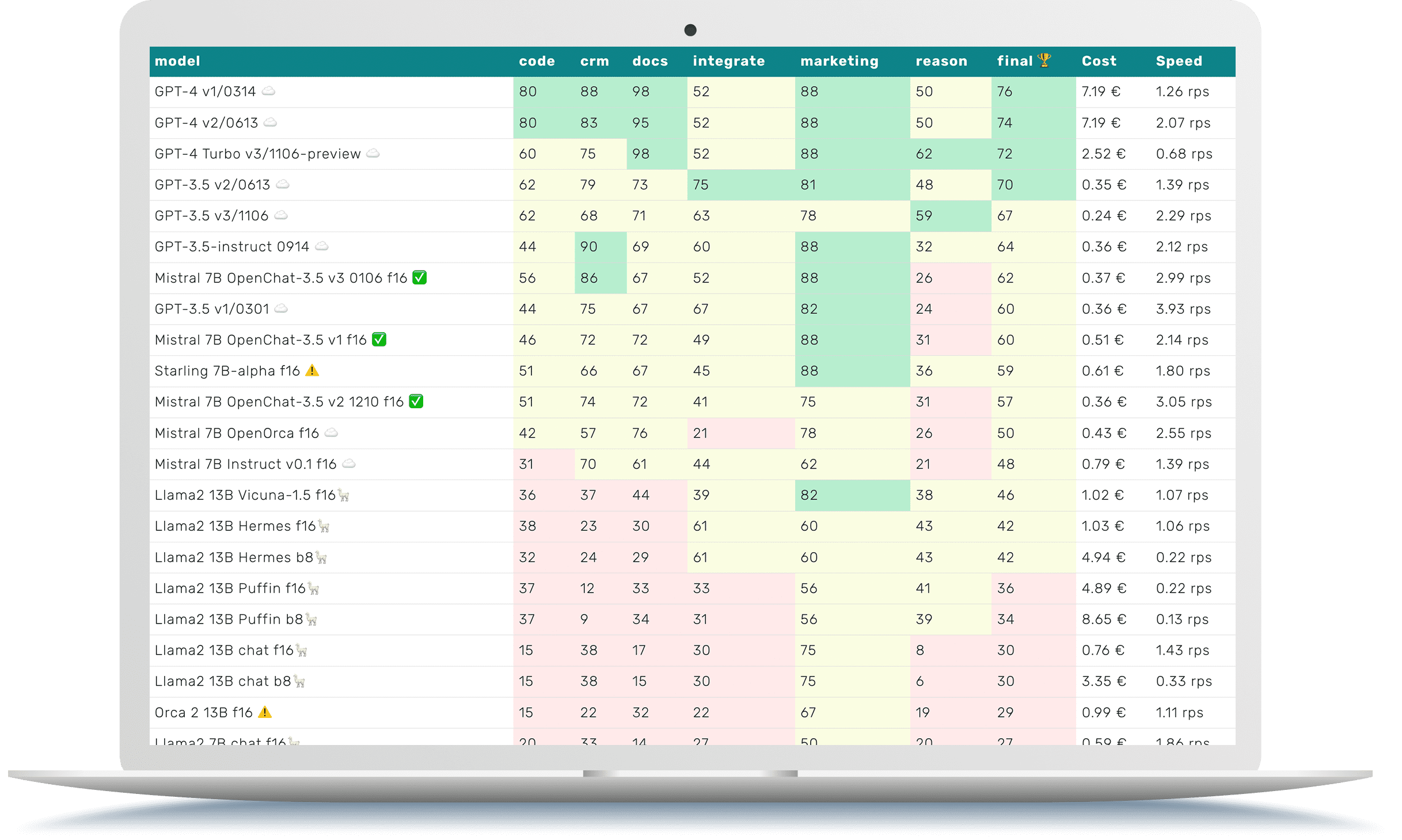
LLM Benchmarks | Jänner 2024
Die Trustbit-Benchmarks bewerten die Modelle in Bezug auf ihre Eignung für die digitale Produktentwicklung. Je höher die Punktezahl, desto besser.
☁️ - Cloud-Modelle mit proprietärer Lizenz
✅ - Open-Source-Modelle, die lokal ohne Einschränkungen ausgeführt werden können
🦙 - Lokale Modelle mit Llama2-Lizenz
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| GPT-3.5 v1/0301 ☁️ | 44 | 75 | 67 | 67 | 82 | 24 | 60 | 0.36 € | 3.93 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 45 | 88 | 36 | 59 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 61 | 44 | 62 | 21 | 48 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 44 | 39 | 82 | 38 | 46 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 33 | 33 | 56 | 41 | 36 | 4.89 € | 0.22 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 34 | 31 | 56 | 39 | 34 | 8.65 € | 0.13 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 30 | 75 | 8 | 30 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 30 | 75 | 6 | 30 | 3.35 € | 0.33 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 14 | 27 | 50 | 20 | 27 | 0.59 € | 1.86 rps |
| Mistral 7B Zephyr-β f16 ✅ | 23 | 34 | 27 | 44 | 29 | 4 | 27 | 0.51 € | 2.14 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 6 | 41 | 48 | 4 | 26 | 0.80 € | 1.37 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 34 | 13 | 58 | 8 | 24 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 20 | 42 | 52 | 12 | 22 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 22 | 18 | 52 | 4 | 18 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 5 | 2 | 28 | 2 | 7 | 1.01 € | 1.08 rps |
Die Benchmark-Kategorien im Detail
Hier erfahren Sie, was wir mit den unterschiedlichen Kategorien der LLM Leaderboards genau untersuchen
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
-
Die geschätzten Kosten für die Ausführung der Arbeitslast. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
-
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Je höher die Geschwindigkeit, desto besser.
Mistral 7B OpenChat v3 (0106) schlägt ChatGPT-3.5
Open-Source-Modelle werden mit jedem vergangenen Monat immer besser. Das sind großartige Neuigkeiten, da Sie diese Modelle lokal auf Ihren Maschinen ausführen können. Unsere Kunden schätzen diese Möglichkeit sehr!
→ Fortschritte bei Open-Source-Modellen: Immer häufiger lokale Ausführungen möglich
→ Mistral 7B OpenChat-3.5: Ein Spitzenkandidat unter den Open-Source-Modellen
Unter diesen Open-Source-Modellen ist einer der besten Kandidaten eine fine-tune Version von Mistral 7B, genannt Mistral 7B OpenChat-3.5. Es bietet eine sehr gute Balance zwischen Qualität, Leistung und den benötigten Rechenressourcen, um es lokal auf Ihrer eigenen Hardware auszuführen.
→ Überlegenheit der dritten Version: Mistral 7B OpenChat-3.5 übertrifft ChatGPT-3.5 in Geschäftsaufgaben
Bis zu diesem Punkt haben wir hauptsächlich die erste Version von Mistral 7B OpenChat-3.5 (fine-tune) verwendet. Unsere jüngsten Benchmarks zeigen jedoch, dass die dritte Version viel besser ist. Sie schlägt sogar ChatGPT-3.5 bei unseren geschäftsorientierten Aufgaben!

Nichtsdestotrotz gibt es noch einen langen Weg zu gehen, da die Version von ChatGPT-3.5, welche von Mistral 7B OpenChat-3.5 übertroffen wurde, die älteste und schwächste ist. Dennoch ist das ein Anfang und wir sind sehr gespannt, was uns in den nächsten Wochen und Monaten erwartet.
Warum gibt es keine Benchmarks für Mixtral 8x7B oder Mistral-Medium?
Sie haben wahrscheinlich schon von einer anderen, viel leistungsfähigeren Version von Mistral gehört: Mixtral 8x7B. Dieses Modell verwendet eine andere Architektur, die als sparse mixture of experts (MoE) bezeichnet wird.
Dieses MoE-Modell ist leistungsfähiger als Mistral 7B. Es treibt auch das gehostete Modell mistral-small von MistralAI an. Wir haben keines dieser Modelle in diesem LLM-Benchmark. Ebenso wenig haben wir das Mistral-Medium-Modell, das noch leistungsfähiger als Mixtral 8X7B ist.
Der Grund, warum wir sie noch nicht in die Benchmarks aufgenommen haben
Die zweite Generation der Mistral-Modelle wurde trainiert, um besser als die erste Generation zu sein. Diese Modelle liefern bessere Antworten, versagen jedoch manchmal darin, dem Antwortformat genau zu folgen, wie es in der Aufforderung und den Few-Shot-Beispielen instruiert wurde. Sie sind ausführlicher als nötig.
Diese Ausführlichkeit macht das Modell weniger nützlich für geschäftsorientierte Aufgaben und die Automatisierung von Geschäftsprozessen.
Natürlich können Sie beim Einsatz des Modells eine Nachbearbeitung hinzufügen, um zusätzliche Erklärungen zu entfernen. Jedoch wäre es unfair gegenüber den anderen Modellen, mistral-spezifische Nachbearbeitungen zu den Trustbit LLM Benchmarks hinzuzufügen, deshalb werden wir das nicht tun.
Trustbits Benchmarks halfen dem AI Team von Mistral, Probleme des Modells besser zu verstehen
Wir haben das Problem den Mistral AI Teams gemeldet und reproduzierbare Beispiele zur Verfügung gestellt. Die Trustbit LLM Benchmarks halfen, die Auswirkungen zu verstehen und den Umfang einzugrenzen: Die erste Generation der Modelle hatte das Problem nicht.
Das Team von Mistral AI kommt schnell voran und arbeitet bereits an dem Problem:
„Unsere Modelle neigen manchmal einfach dazu, ausschweifend zu sein... Unser Team arbeitet ebenfalls daran und wird es verbessern.“
Benchmark-Update nach Behebung des Problems
Zu diesem Zeitpunkt haben wir entschieden, die aktuellen Benchmark-Ergebnisse von mistral-tiny/mistral-small/mistral-medium nicht einzubeziehen, da es sich lediglich um einen vorübergehenden Mangel handelt, der bald behoben wird. Sobald dies geschieht, werden wir ein Update zu den Benchmarks veröffentlichen.
Planung synthetischer Benchmarks: Assistenten, Q&A und RAGs
Obwohl rohe LLM-Benchmarks interessant und aufregend sind, können sie manchmal zu technisch und nicht besonders relevant sein.
Wie wir mit unseren Kunden gelernt haben, ist die Leistung eines LLM nur einer von vielen Faktoren, die zu dem Wert beitragen, den ein vollständiges Produkt oder ein Dienst bieten kann. Zu diesem Zeitpunkt denken wir darüber nach, einen weiteren synthetischen Benchmark zu erstellen - einen, um die Leistung kompletter KI-Systeme bei geschäftsspezifischen Aufgaben zu bewerten.
Zum Beispiel:
die richtige Antwort in einem großen PDF finden
eine korrekte Antwort synthetisieren, die das Nachschlagen mehrerer Dokumente erfordert
eingehende Dokumentation korrekt bewerten und verarbeiten
Ihre Meinung ist gefragt: Welche geschäftsspezifischen Aufgaben sollten wir benchmarken?
Gibt es andere geschäftsspezifische Aufgaben, die Sie gerne in unserem Benchmarkt sehen würden? Wir sind gespannt auf Ihren Input und freuen uns sehr, wenn Sie uns schreiben!
Gerne können Sie auch Kontakt aufnehmen, um einen Einblick in einen solchen Benchmark zu erhalten, bevor er veröffentlicht wird.
Trustbit LLM Benchmarks Archiv

Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!