Benchmarks für ChatGPT und Co
Februar 2024

Die Highlights des Monats:
Verbesserungen bei ChatGPT-4
Leistungsvergleiche für die Mistral-API und die Anthropic Claude-Modelle
Erste Arbeiten an Enterprise-AI-Benchmarks
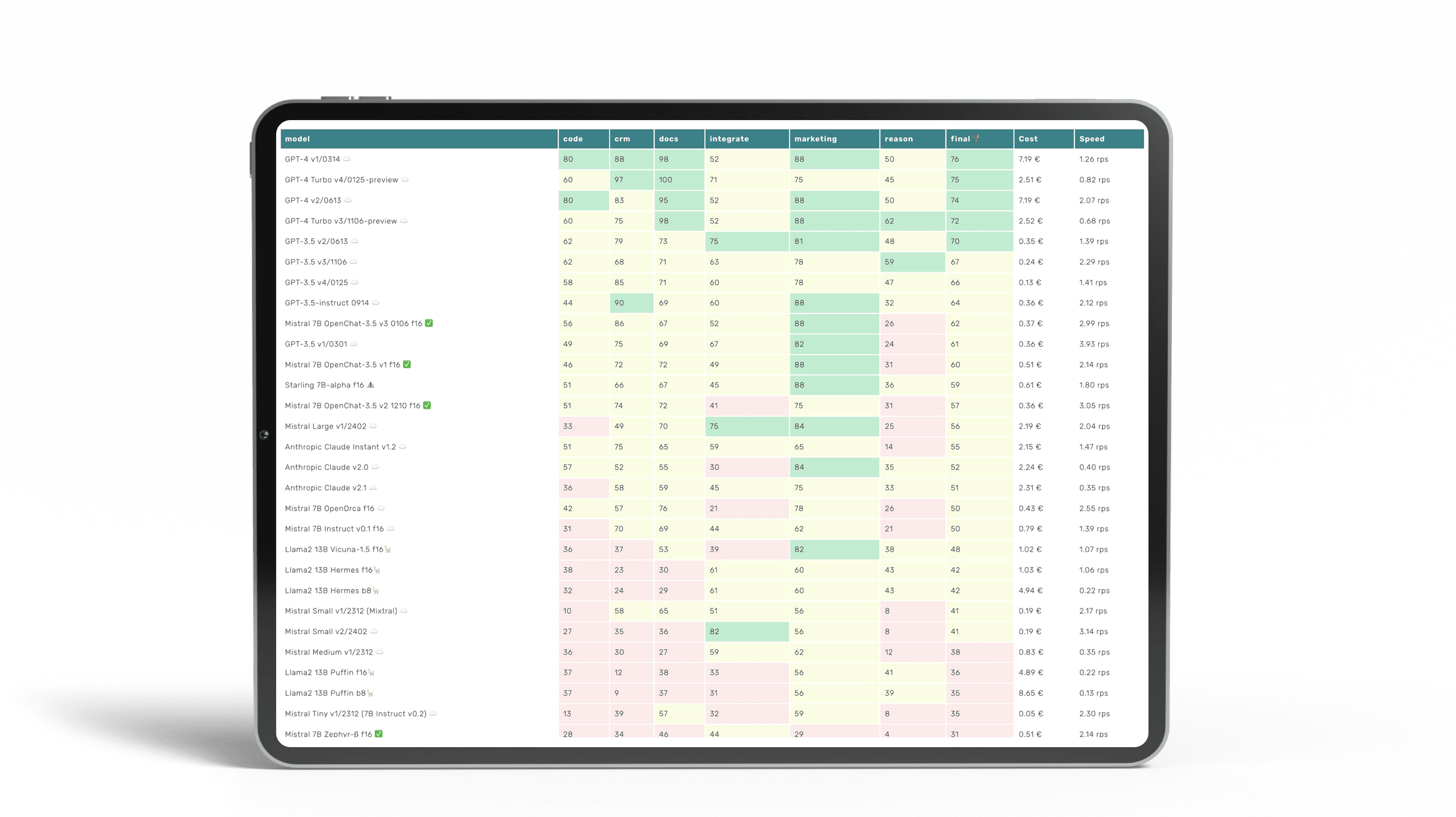
LLM Benchmarks | Februar 2024
Die Trustbit-Benchmarks bewerten die Modelle in Bezug auf ihre Eignung für die digitale Produktentwicklung. Je höher die Punktezahl, desto besser.
☁️ - Cloud-Modelle mit proprietärer Lizenz
✅ - Open-Source-Modelle, die lokal ohne Einschränkungen ausgeführt werden können
🦙 - Lokale Modelle mit Llama2-Lizenz
Hier ist ein aktualisierter Bericht zur Leistung von LLM-Modellen in Enterprise-spezifischen Workloads.
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
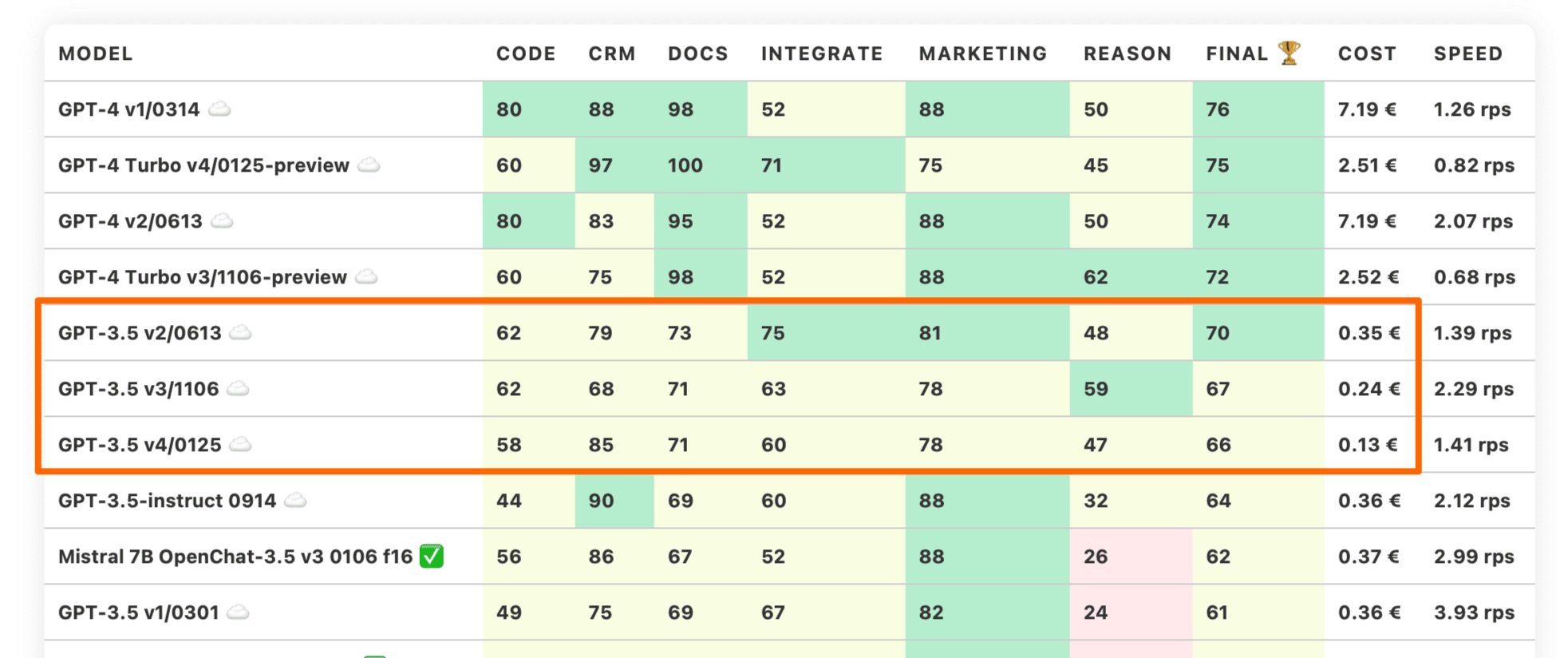
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 45 | 88 | 36 | 59 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 30 | 84 | 35 | 52 | 2.24 € | 0.40 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 45 | 75 | 33 | 51 | 2.31 € | 0.35 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 33 | 56 | 41 | 36 | 4.89 € | 0.22 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 31 | 56 | 39 | 35 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 32 | 59 | 8 | 35 | 0.05 € | 2.30 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 30 | 75 | 8 | 30 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 30 | 75 | 6 | 30 | 3.35 € | 0.33 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 27 | 50 | 20 | 28 | 0.59 € | 1.86 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 2 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
Die Benchmark-Kategorien im Detail
Hier erfahren Sie, was wir mit den unterschiedlichen Kategorien der LLM Leaderboards genau untersuchen
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
-
Die geschätzten Kosten für die Ausführung der Arbeitslast. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
-
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Je höher die Geschwindigkeit, desto besser.
Verbesserungen in Chat-GPT-4 - neue Empfehlungen
Das neueste Update in der ChatGPT-v4-Reihe bricht endlich den Trend, günstigere Modelle mit geringerer Genauigkeit zu veröffentlichen. In unseren Benchmarks schlägt das GPT-4 0125 (oder v4) endlich das GPT-4 0613 (oder v2) Modell.
Dieses Modell enthält auch die neuesten Trainingsdaten (bis Dezember 2023) und läuft zu einem Bruchteil der Kosten der Modelle v1 und v2. Dies macht das GPT-4 Turbo v4/0125-preview zu einem neuen sicheren Standardmodell, das wir empfehlen können.

Der Trend bei den GPT-3.5-Modellen folgt weiterhin dem Muster. Neue Modelle werden günstiger und weniger leistungsfähig.
Mistral und Claude API - Verbosity Problem
Dieser Benchmark umfasst endlich Benchmarks für die Mistral AI und Anthropic Claude Modelle:
Anthropic Claude Instant v1.2
Kleineres LLM von Anthropic - es ist anthropic.claude-instant-v1 auf AWS Bedrock.
Anthropic Claude v2.1 und v2.1
Größere Anthropic LLMs, die große Kontextgrößen eingeführt haben - anthropic.claude-v2 Serie auf AWS Bedrock.
Mistral Large Model
Kürzlich veröffentlichtes LLM von Mistral, das sich zwischen GPT4 und GPT3.5 in internen Benchmarks positioniert. Es ist mistral-large-2402 auf La Plateforme.
Mistral Medium
Ein weiteres proprietäres Modell von Mistral, das in etwa mit Llama 70B vergleichbar ist, laut Miqu-Leak. Wir testen mistral-medium-2312.
Mistral Small
Dieses Modell war ein sehr beliebtes Mixtral 8x7B, jedoch sagt die zweite Version nicht, ob dies immer noch der Fall ist. Wir testen beide Versionen: mistral-small-2402 und mistral-small-2312.
Mistral Tiny
Dieses Modell entspricht Mistral 7B Instruct v0.2. Oder mistral-tiny-2312 auf Mistral AI.
All diese Modelle können gut für das Erstellen von Inhalten und das Kommunizieren mit Menschen sein. Das ist jedoch nicht der Punkt unseres Benchmarks. Wir ordnen die Modelle auf der Rangliste nach ihrer Fähigkeit, exakte Antworten in Aufgaben wie Informationswiederherstellung, Dokumentenranking oder Klassifizierung zu liefern.
All diese Modelle sind dafür zu wortreich. Sie folgen Anweisungen auch nicht präzise. Selbst lokale Kleinserien von Mistral 7B sind dazu besser in der Lage. ChatGPT-4 bleibt an der Spitze. Es scheint, als würde OpenAI die Bedürfnisse von Unternehmenskunden besser verstehen als der Rest.

UNSER FAZIT
Wenn Sie LLMs für Chatbots und Marketingzwecke benötigen und damit einverstanden sind, dass einige Anweisungen ignoriert werden, könnten sich die Mistral AI- und Anthropic-Modelle lohnen, näher anzusehen. Andernfalls empfehlen wir, diese Modelle vorerst nicht zu nutzen.
Wir stellen vor
Enterprise AI Leaderboard
Wir verfolgen die Leistung von LLM-Modellen seit vielen Monaten, dies ist unser achter Bericht.
Dieser Prozess hat uns geholfen, aus erster Hand Erfahrungen im Umgang mit mehreren verschiedenen Modellen gleichzeitig zu sammeln. Anders als bei den üblichen akademischen Benchmarks beziehen wir Daten aus realen Projekten und unternehmensspezifischen Aufgaben.
⭐️ Neu: LLM Benchmarks von patronus ai
Übrigens sind wir nicht mehr allein in diesem Bereich. Ein anderes Unternehmen hat kürzlich begonnen, an einem ähnlichen Satz von Enterprise Benchmarks zu arbeiten. Wir laden Sie ein, einen Blick auf das Enterprise Scenarios Leaderboard auf Hugging Face von PatronusAI zu werfen.
Das ist alles gut, aber es ist an der Zeit, den wahren Elefanten im Raum anzusprechen. Die Wahrheit ist:
Große Sprachmodelle sind nur ein Implementierungsdetail.
Ja, es stimmt, dass viel von ihrer Leistung und ihren Fähigkeiten abhängt. Deshalb empfehlen wir beispielsweise kurzfristig allgemein GPT-4 Turbo v4/0125-preview als Modell, mit dem man beginnen sollte.
Wir glauben jedoch letztendlich, dass die großen Sprachmodelle ersetzbar und austauschbar sind. Tatsächlich wurde die gesamte LLM-Rangliste gestartet wegen einer sich wiederholenden Kundenfrage: „Wann kann ich ChatGPT-4 in meinen Projekten durch ein lokales Modell ersetzen?“
Wenn Sie sich die „Request For Startups“ vom YCombinator anschauen, konzentriert sich eine spezifische Anfrage genau auf das Thema des Ersatzes: Kleine feinabgestimmte Modelle als Alternative zu riesigen generischen Modellen. YCombinator half Unternehmen wie Stripe, Dropbox, Twitch und Cruise zu inkubieren. Sie wissen ein oder zwei Dinge, wenn es um Markttrends und Branchentrends geht.
Riesige generische Modelle mit vielen Parametern sind sehr beeindruckend. Aber sie sind auch sehr kostspielig und bringen oft Latenz- und Datenschutzherausforderungen mit sich. Glücklicherweise haben kleinere Open-Source-Modelle wie Llama2 und Mistral bereits gezeigt, dass sie, wenn sie feinabgestimmt mit geeigneten Daten sind, vergleichbare Ergebnisse zu einem Bruchteil der Kosten liefern können.
Um das Konzept noch weiter voranzutreiben, glauben wir, dass die lokalen großen Modelle der Weg sein werden, um die Gesamtgenauigkeit des Systems über die Fähigkeiten von ChatGPT hinaus zu verbessern, während die Betriebskosten erheblich gesenkt werden.
hinweis
Die Anpassung pro System macht es möglich, Systeme zu entwerfen, die lernen und sich an die Besonderheiten jedes einzelnen Unternehmens anpassen. Wir sprechen hier noch nicht einmal über fortgeschrittene Themen wie das Feinabstimmen (dies erfordert eine Menge hochwertiger Daten). Selbst eine einfache Anpassung von Aufforderung und Kontext basierend auf der Statistik kann Wunder bewirken.
Da individuelle LLMs ein Implementierungsdetail sind, was sollte die Metrik sein, um den Stand der Technik zu messen, wenn KI bei Unternehmenslasten angewendet wird?
Hier ist ein Hinweis in Form einiger Fragen, die uns gestellt werden:
Welche RAG-Architektur ist die beste für rechtliche Workloads?
Welche Vektor-Datenbank sollten wir verwenden, um einen internen Support-Bot zu bauen?
Was ist der beste Ansatz, um automatisch Unternehmensfragebögen mit 1000 Fragen im B2B-Verkauf zu handhaben?
Die Metrik sollte vollständige Unternehmens- und Geschäfts-KI-Lösungen anvisieren und vergleichen. End-to-End.
Jeder kann eine 99%ige Genauigkeit bei RAG-Aufgaben beanspruchen. Wir möchten dies unabhängig überprüfen, eine bessere Intuition über verschiedene Architekturen aufbauen und letztendlich unseren Kunden ermöglichen, Entscheidungen auf Basis vertrauenswürdiger Tests zu treffen.
Es wird Zeit und Mühe erfordern, eine vollständige Unternehmens-KI-Rangliste aufzubauen. Wir beginnen mit der grundlegenden Fähigkeit - der Fähigkeit des KI-Systems, relevante Informationen innerhalb der unternehmensspezifischen Dokumentation zu finden. Dies ist der Grundbaustein von RAG-Systemen.
Hier ist ein Beispiel: Wir haben einen öffentlichen Jahresbericht der Christian Dior Gruppe genommen. Dann stellten wir dem KI-System 10 spezifische Fragen zu diesem Bericht. Zum Beispiel:
Was war der Unternehmensumsatz im Jahr 2022?
Wie viel Liquidität hatte das Unternehmen am Ende des Jahres 2021?
Was war die Bruttomarge im Jahr 2023?
Wie viele Mitarbeiter hatte das Unternehmen im Jahr 2022?
Wie Sie sehen, hat jede Frage nur eine einzige korrekte Antwort. Es sind keine Berechnungen oder fortgeschrittenes Denken erforderlich.
Wie gut, denken Sie, würden verschiedene Systeme diese spezifischen Fragen behandeln?
Nicht so gut!
Wir haben für den Anfang einige gängige Systeme getestet:
ChatGPT-4
OpenAI Assistant API mit Dokumentenabruf und gpt-4-0125 Modell
Zwei beliebte Dienste zum Stellen von Fragen zu einem spezifischen PDF: ChatPDF und AskYourPDF.
Jeder Test beinhaltete das Hochladen des Jahresberichts und das Stellen der Frage mit einer sehr spezifischen Anweisung:
PROMT
Antworte mit einer Gleitkommazahl in aktueller Währung, zum Beispiel "1,234 Millionen", verwende das Dezimalkomma und keine Tausendertrennzeichen. du kannst die Antwort durchdenken, aber die letzte Zeile sollte in diesem Format sein "Antwort = Zahl Einheit". Antworte mit "Antwort = Keine", wenn keine Informationen verfügbar sind.
Diese Anweisung war wichtig, weil:
wir möchten Modelle ermutigen, den chain-thought-of-process (CoT) zu verwenden, wenn das die Genauigkeit erhöht
wir benötigen trotzdem die Zahl in einem spezifischen Lokale lesbar, daher die strenge Anforderung, das Dezimalkomma zu verwenden und keine Tausendertrennzeichen (genau wie im Originalbericht).
Offensichtlich hätten RAG-Systeme, als End-to-End-Lösungen, CoT bereits in die Pipelines unter den Kulissen integriert. Jedoch, als wir die Anweisung in die Gesamtanfrage einfügten, erhöhte sich die Gesamtgenauigkeit dennoch.
Unten sind die Endnoten mehrerer RAG-Systeme in einem einzigen Test. Wir gaben jedem System 1 Punkt für eine korrekte und lesbare Antwort. 0,5 Punkte für eine Antwort, die die richtige Information herauszog, aber einen Fehler in der Größenordnung machte.
| Question | Answer | ChatGPT-4 | gpt-4-0125 RAG | ChatPDF | Ask Your PDF |
|---|---|---|---|---|---|
| How much liquidity did this company have at hand at the end of 2021? | 8,122 million | 7,388 million euro | 7,918 million | 10,667 million euros | INVALID |
| How much liquidity did this company have at hand at the end of 2022? | 7,588 million | 7,388 billion euros | 7,388 million | 11.2 billion euros | 7588 million euros |
| How many employees did the company have at the end of 2022? | 196006 | 196,006 | 196,006 | 196006 | INVALID |
| How much were total lease liabilities of the company by the end of 2021? | 14,275 million | 14,275 million | 14.275 million | 14,275 | 14,275 million euros |
| What amount was recorded for the repayment of lease liabilities in 2022? | 2,453 million | 2,453 million | 2.711 million | 2,711 million | 2,711 million euros |
| What was the company's net revenue in 2021? | 64,215 million | 64,215 million | 64,215 million | 64,215 million euros | 64.215 million euros |
| What was the company's net revenue in 2022? | 79,184 million | 79,184 million | 79184 million euros | 79,184 million EUR | 79,184 million EUR |
| What was the company's net revenue in 2023? | None | None | None | None | INVALID |
| What was the total shareholder equity at the end of 2022? | 54,314 million | 54,3 billion | 54,314 million | 54.314 billion euros | INVALID |
| What was the company's gross margin for the year 2021? | 43,860 million | 43,860 million euros | 43,860 million | 43,860 million euros | 43,860 million euros |
| SCORE | 100 | 70 | 60 | 55 | 40 |
Bisher sind RAG-Systeme von OpenAI die besten auf dem Markt für die vorliegende Aufgabe. Wir erwarten jedoch, dass dies nicht lange so bleiben wird.
Spezialisierte Lösungen sind in der Lage, höhere Punktzahlen zu erreichen, auch ohne den Einsatz von topaktuellen LLMs. Wir wissen das sicher, denn wir haben solche Systeme gebaut. Eines davon beinhaltet sogar die Verwendung von Mistral-7B-OpenChat-3.5, um Informationen aus Zehntausenden von PDF-Dokumenten zu extrahieren.
In dem Maße, wie wir diesen Enterprise AI-Benchmark erweitern und um mehr Fälle und Lösungen bereichern, ist zu erwarten, dass ChatGPT letztendlich entthront wird.
Trustbit LLM Benchmarks Archiv

Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!