Dezember 2023
Benchmarks für ChatGPT & Co:


Die Weihnachtsferien stehen bevor, deshalb haben wir diesmal etwas Besonderes vorbereitet!
Neuer Trustbit LLM Sprach-Benchmark
Neue Modelle: Starling 7B, Notus 7B und Microsoft Orca
Alle lokalen Modelle wurden mit aktivem Beam Search neu berechnet.
Multilinguale Trustbit LLM Benchmarks
Haben Sie gehört, dass ChatGPT besser mit der englischen Sprache funktioniert und möglicherweise weniger effizient mit anderen Sprachen umgehen kann?
Dies ist unter den Anwender:innen bekannt. Es betrifft nicht nur ChatGPT, sondern auch andere große Sprachmodelle. Die Hauptursache liegt darin, dass im Trainingsdatensatz viel mehr Englisch enthalten ist als andere Sprachen.
Die Konsequenz ist, dass ChatGPT plötzlich weniger leistungsfähig werden kann, wenn es mit Texten in anderen Sprachen umgehen muss. Die Ergebnisse werden weniger genau sein, und die Rate der Halluzinationen nimmt zu.
Das könnte für internationale Unternehmen, die KI-Fähigkeiten für mehrere Sprachen entwickeln möchten, als unangenehme Überraschung kommen.
Die zentrale Frage lautet daher:
Wie gut kann ChatGPT die Sprachen meines Unternehmens sprechen?
Um unseren Kunden dabei zu helfen, sich im Bereich der mehrsprachigen KI besser zurechtzufinden, hat Trustbit den mehrsprachigen Benchmark für große Sprachmodelle erstellt.
Diese erste Veröffentlichung vergleicht die Leistung von LLM-Modellen in 16 verschiedenen Sprachen, angefangen bei Englisch und Deutsch bis hin zu Ukrainisch und Schwedisch.
Dieser Benchmark wurde mit Hilfe von Expert:innen für Linguistik und unseren Trustbit-Kolleg:innen erstellt (sie leben in unterschiedlichen Ländern). Jede Sprache wurde von einem Muttersprachler beigetragen.
Der Multilingual LLM Benchmark von Trustbit geht nicht so tief in die Fähigkeiten der Modelle ein wie unser Produkt-Benchmark. Er konzentriert sich auf grundlegende sprachliche Fähigkeiten:
- Verstehen und Ausführen von Anweisungen in einer bestimmten Sprache.
- Wörter in einer Sprache verstehen, über sie nachdenken und Bedeutungen ableiten.
Dies ist bereits ausreichend, um die Leistung verschiedener Modelle in einer Sprache zu vergleichen oder herauszufinden, welche Sprachen von einem Modell Ihrer Wahl gut unterstützt werden.
Eine Genauigkeit von 100 bedeutet, dass das Modell in der Lage war, alle Anweisungen auszuführen. Eine Genauigkeit von 50 bedeutet, dass es die Hälfte der Aufgaben falsch gemacht hat.
Die Abkürzungen in der Tabelle stehen für:
BAK: Bashkir, CHV: Tschuwaschisch, DEU: Deutsch, ENG: Englisch, FRA: Französisch, HUN: Ungarisch, KPV: Komi-Syrjänisch, KRC: Karatschai-Balkarisch, KUM: Kumykisch, MHR: Östliches Mari, POL: Polnisch, POR: Portugiesisch, RUS: Russisch, SAH: Jakutisch, SWE: Schwedisch, TAT: Tatisch, UDM: Udmurtisch, UKR: Ukrainisch

Conclusio
Wie man sieht, ist von den 16 bewerteten Sprachen und 25 Modellen nur ChatGPT wirklich fließend in mehreren Sprachen. Die anderen Modell-Sprachen Kombinationen werden weniger unterstützt.
Meine Sprache wird von LLMs nicht unterstützt. Was nun?
Wenn einige Sprachen von einem generativen KI-Modell Ihrer Wahl nicht gut unterstützt werden, gibt es dennoch mehrere Optionen, KI effektiv einzusetzen.
Als Teil der Trustbit-Forschung und Entwicklung arbeiten wir mit ressourcenarmen Sprachen (Sprachen, die von 0,01 % der Weltbevölkerung oder noch weniger gesprochen werden). Ein Teil dieses Fachwissens lässt sich auch als Erkenntnisse für KI-gesteuerte Business-Systeme übertragen:
1. Verwenden Sie automatisierte Übersetzungen, um Anfragen ins Englische zu konvertieren und dann die Ergebnisse zurückzuführen. Es ist einfacher, ein hervorragendes Übersetzungsmodell zu trainieren, als ein gutes Grundlagenmodell zu erstellen.
2. Übermitteln Sie sowohl den Text der Übersetzung als auch den Originaltext auf Anfrage an LLMs.
3. Nicht-englische Sprachen können pro Anfrage mehr Tokens verwenden. Dies führt zu kleineren effektiven Kontextfenstern und teureren Anfragen. Achten Sie daher auf die Token-Nutzung in Ihren Anfragen.
4. Stellen Sie sicher, dass Sie der Anfrage ”Die Sprache [nennen Sie die gewünscht Sprache] ist Ihre Muttersprache" voranstellen, um sicherzustellen, dass das Sprachmodell von Anfang an zum richtigen Kontext wechselt.
5. Verwenden Sie Retrieval-Augmented Generation (RAG), um relevante domänenspezifische Schnipselinformationen in die KI-Anfragen einzubeziehen. Verwenden Sie dafür sprachspezifische Einbettungen. Bereichern Sie den Kontext mit von GPT generierten Hinweisen, selbst wenn Sie die endgültige Inferenz auf lokalen Modellen durchführen.
6. Wenn Sie eine sprachbasierte Interaktion aufbauen, versuchen Sie, Multi-Modal-Modelle zu verwenden (z.B. mappt Audioanfragen direkt auf Englisch über den gemeinsamen Vektorraum). Dies reduziert die Anzahl der semantischen "Hops", die die Genauigkeit beeinflussen.
Wie schreibt man einen schlechten mehrsprachigen Benchmark?
Ein guter Benchmark erfordert Aufwand, Zusammenarbeit mit Linguisten und GPU-Zeit. Bei all diesen Investitionen haben wir festgestellt, dass es trivial ist, einen Benchmark zu schreiben, bei dem sogar ChatGPT 4 scheitern wird.
Hier sind zwei einfache Fragen auf Englisch:

Die erste Antwort ist offensichtlich falsch, weil es drei reimende Wörter gibt: "mouse", "house" und "spouse". Die zweite Antwort ist falsch, weil die Betonung auf der dritten Silbe liegt, nicht auf der zweiten.
Bedeutet das, dass ChatGPT 4 schlecht mit englischer Sprache umgeht? Nein, das bedeutet nur, dass dies ein schlechter Benchmark ist, um die sprachlichen Fähigkeiten zu beurteilen. Die Aufgaben des Reimens oder der Betonung von Silben sind intuitiv für Menschen, die durch Zuhören und Sprechen lernen. Textbasierte große Sprachmodelle (wie ChatGPT oder Llama) lernen aber nur durch Lesen und Schreiben.
Zusätzlich ist dieser Benchmark nicht nützlich, weil er sinnvolle Vergleiche von Modellen über verschiedene Sprachen hinweg verhindert. Immerhin erfolgt Reimen in verschiedenen Sprachen unterschiedlich. Tonale Sprachen, wie zum Beispiel Chinesisch, können tonale Muster (also die Änderungen der Tonhöhen beim Sprechen) in Reimschemata integrieren. Die besonderen Merkmale einer jeden Sprache beeinflussen, wie in ihren jeweiligen sprachlichen Gefügen Reime und Rhythmus gestaltet werden.
Bei der Erstellung des Multilingual Trustbit LLM Benchmarks haben wir versucht, diese und viele andere linguistische Feinheiten zu berücksichtigen.
Bei der Entwicklung des Multilingualen Trustbit LLM-Benchmarks haben wir versucht, diese und viele andere sprachliche Feinheiten zu berücksichtigen.
Neue Modelle
Wir haben neue Modelle im Benchmark:
Starling 7B-alpha - weitere Feinabstimmung auf Basis von OpenChat 3.5
Mistral 7B Notus-v1 - eine weitere vielversprechende Mistral-Feinabstimmung (LoRA)
Microsoft Orca 2 13B und 7B - ein neues grundlegendes Modell von Microsoft.
Diese Modelle sind sowohl im klassischen Trustbit LLM Benchmark als auch im mehrsprachigen Benchmark enthalten.
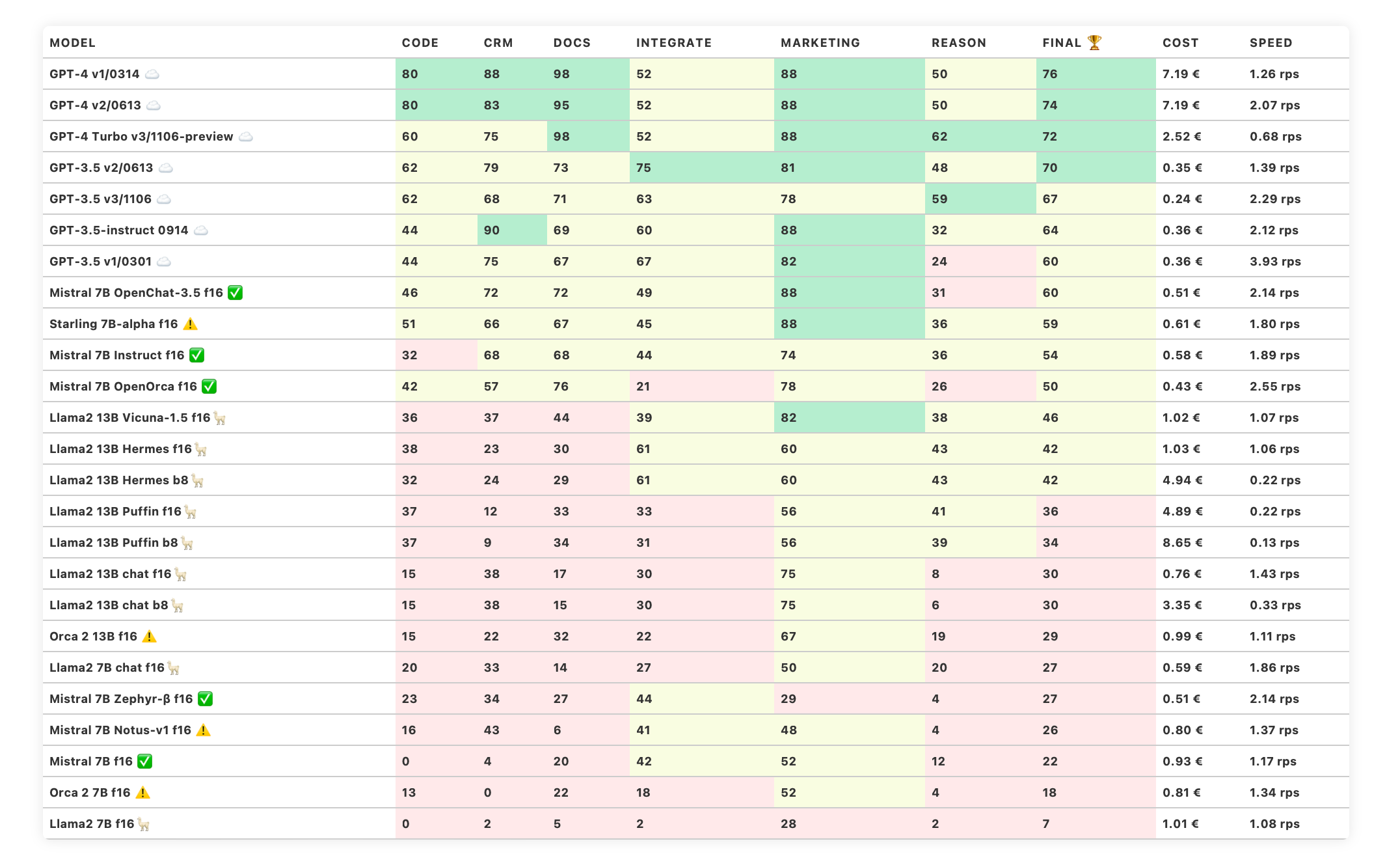
Die Benchmark-Kategorien im Detail
-
Wie gut kann das Modell mit großen Dokumenten und Wissensdatenbanken arbeiten?
-
Wie gut unterstützt das Modell die Arbeit mit Produktkatalogen und Marktplätzen?
-
Kann das Modell problemlos mit externen APIs, Diensten und Plugins interagieren?
-
Wie gut kann das Modell bei Marketingaktivitäten unterstützen, z.B. beim Brainstorming, der Ideenfindung und der Textgenerierung?
-
Wie gut kann das Modell in einem gegebenen Kontext logisch denken und Schlussfolgerungen ziehen?
-
Kann das Modell Code generieren und bei der Programmierung helfen?
-
Die geschätzten Kosten für die Ausführung der Arbeitslast. Für cloud-basierte Modelle berechnen wir die Kosten gemäß der Preisgestaltung. Für lokale Modelle schätzen wir die Kosten auf Grundlage der GPU-Anforderungen für jedes Modell, der GPU-Mietkosten, der Modellgeschwindigkeit und des operationellen Overheads.
-
Die Spalte "Speed" gibt die geschätzte Geschwindigkeit des Modells in Anfragen pro Sekunde an (ohne Batching). Je höher die Geschwindigkeit, desto besser.
Statistik
Wussten Sie, dass wir für die Erstellung dieser beiden Tabellen 12.150 Chat-Vervollständigungen (Prompts) durchführen mussten? Oder sogar noch mehr, wenn Sie die Optimierung durch Beam Search berücksichtigen, die nun für alle verfügbaren Modelle aktiviert ist.
Trustbit LLM Benchmarks Archiv

Interessiert an den Benchmarks der vergangenen Monate? Alle Links dazu finden Sie auf unserer LLM Benchmarks-Übersichtsseite!