September 2023
Benchmarks for ChatGPT & Co:


New every month: The Trustbit LLM Leaderboard is a monthly updated comparison of different Large Language Models like ChatGPT and others available to evaluate their applicability in product development.
Trustbit Leaderboard September 2023
The Trustbit benchmarks evaluate the models in terms of their suitability for digital product development. The higher the score, the better.
We distinguish between proprietary cloud models and open source models with generous licenses:
☁️ Identifies cloud models (proprietary)
✅ Identifies open source models that can be run locally.
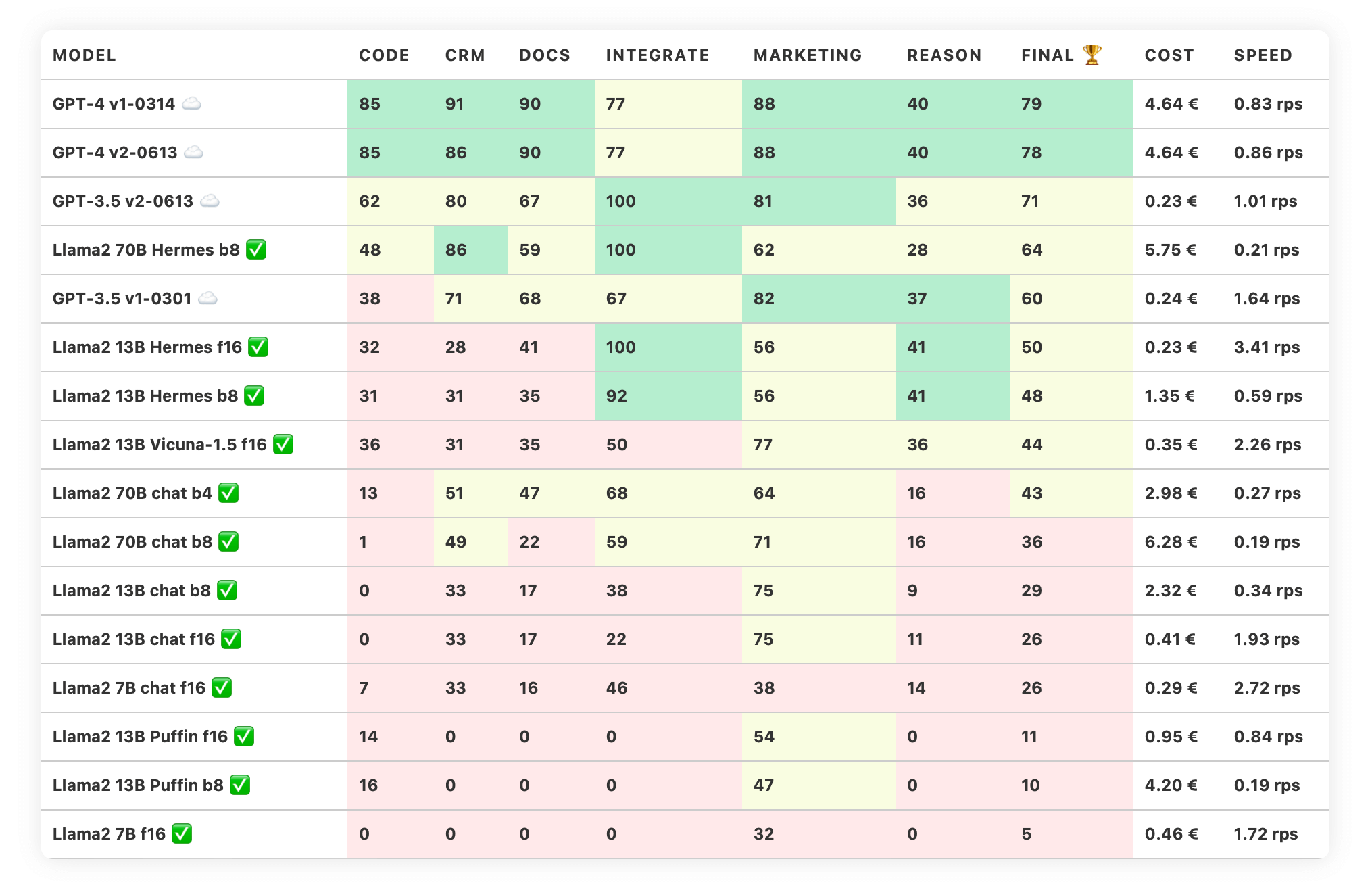
The Cost column shows the estimated cost of running the workload. For cloud-based models, we calculate the cost according to the pricing. For on-premises models, we estimate the cost based on GPU requirements for each model, GPU rental cost, model speed, and operational overhead.
The "Speed" column indicates the estimated speed of the model in requests per second (without batching). A higher speed is better.
On a strategic level, the GPT/LLM landscape is improving month by month. We expect to be able to move some projects from cloud services to on-premises models starting in 2024.
Notable improvements include:
The release of Llama 2 by Meta, which stimulates another round of innovation through its generous license.
The releases of Code Llama and the language-independent model "Sonar". These are not included in this benchmark, but complement generic LLMs. They work particularly well with company-specific assistance systems for certain specialist areas.
Surprising results in benchmarking Llama2 and Nous Hermes 70B
When benchmarking new promising models, it surprisingly turned out that Llama2 itself is not particularly well suited for developing LLM-driven products. It is too talky. However, there are open fine tunings of Llama2 that work particularly well, notably Nous Hermes 70B. This is the first open model to beat ChatGPT 3.5 in our benchmarks.
Cost and quality: The 70B model in comparison
This 70B model can be a bit expensive to run. Running a workload equivalent to this benchmark costs about ~5.75 EUR on a GPU machine rented from a large cloud provider. However, this is just the beginning of the larger trend of improving quality at an affordable cost. Llama 2's 13B fine-tuning is catching up, while the new Falcon 180B model is putting pressure on the top.
In addition, less powerful models are still worth a look, especially as we discover and deploy new forms of guidance and domain-specific beam search.
Trustbit LLM Benchmarks Archive

Interested in the benchmarks of the past months? You can find all the links on our LLM Benchmarks overview page!