Benchmarks for ChatGPT and Co
May 2024

Highlights of the latest models
New Google Gemini 1.5 version - better than the previous ones
GPT-4o - best in this benchmark, but has caveats
Qwen1.5 Chat - one of the best downloadable models
IBM Granite Code Instruct - decent coding results with clean data provenance
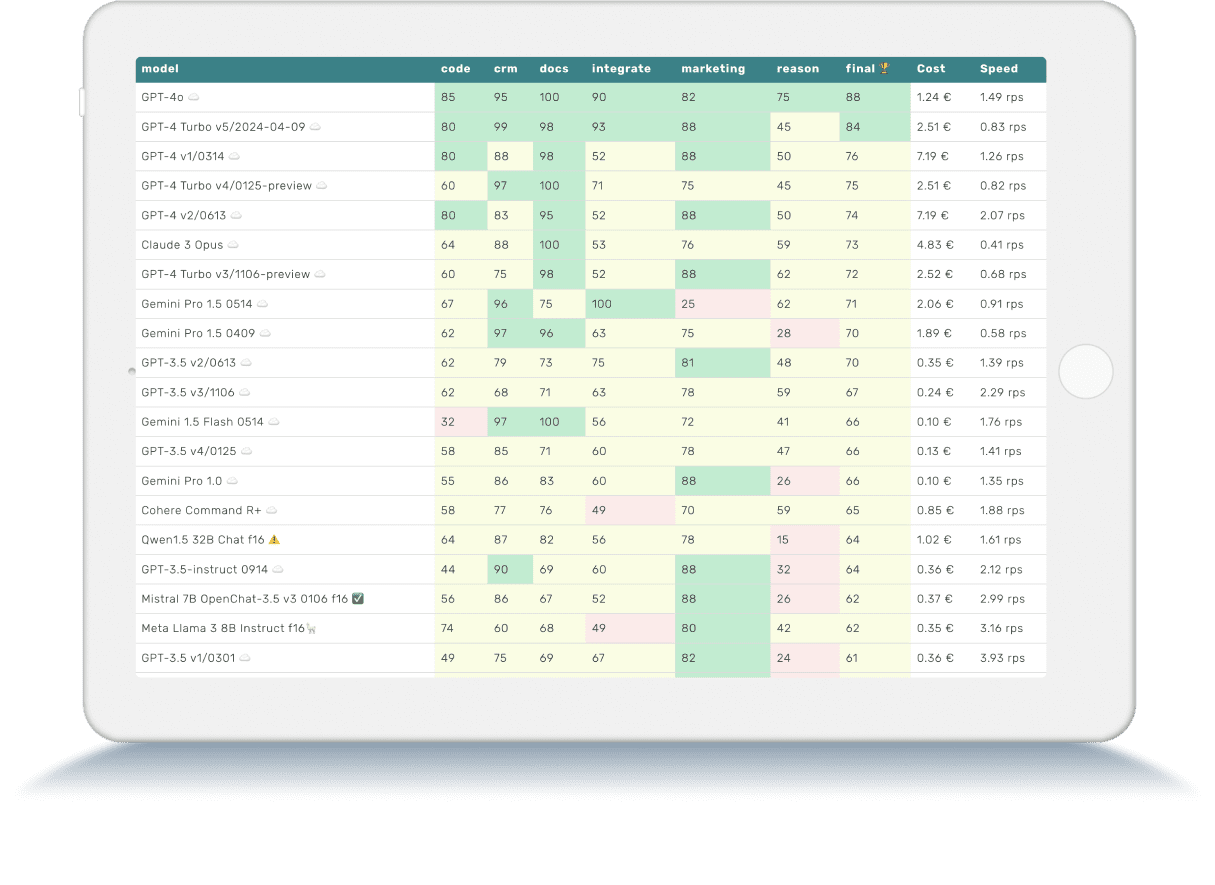
LLM Benchmarks | May 2024
The Trustbit benchmarks evaluate the models in terms of their suitability for digital product development. The higher the score, the better.
☁️ - Cloud models with proprietary license
✅ - Open source models that can be run locally without restrictions
🦙 - Local models with Llama license
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4o ☁️ | 85 | 95 | 100 | 90 | 82 | 75 | 88 | 1.24 € | 1.49 rps |
| GPT-4 Turbo v5/2024-04-09 ☁️ | 80 | 99 | 98 | 93 | 88 | 45 | 84 | 2.51 € | 0.83 rps |
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| Claude 3 Opus ☁️ | 64 | 88 | 100 | 53 | 76 | 59 | 73 | 4.83 € | 0.41 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| Gemini Pro 1.5 0514 ☁️ | 67 | 96 | 75 | 100 | 25 | 62 | 71 | 2.06 € | 0.91 rps |
| Gemini Pro 1.5 0409 ☁️ | 62 | 97 | 96 | 63 | 75 | 28 | 70 | 1.89 € | 0.58 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| Gemini 1.5 Flash 0514 ☁️ | 32 | 97 | 100 | 56 | 72 | 41 | 66 | 0.10 € | 1.76 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| Gemini Pro 1.0 ☁️ | 55 | 86 | 83 | 60 | 88 | 26 | 66 | 0.10 € | 1.35 rps |
| Cohere Command R+ ☁️ | 58 | 77 | 76 | 49 | 70 | 59 | 65 | 0.85 € | 1.88 rps |
| Qwen1.5 32B Chat f16 ⚠️ | 64 | 87 | 82 | 56 | 78 | 15 | 64 | 1.02 € | 1.61 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| Meta Llama 3 8B Instruct f16🦙 | 74 | 60 | 68 | 49 | 80 | 42 | 62 | 0.35 € | 3.16 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 52 | 88 | 36 | 60 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Claude 3 Haiku ☁️ | 59 | 69 | 64 | 55 | 75 | 33 | 59 | 0.08 € | 0.53 rps |
| Mixtral 8x22B API (Instruct) ☁️ | 47 | 62 | 62 | 94 | 75 | 7 | 58 | 0.18 € | 3.01 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Claude 3 Sonnet ☁️ | 67 | 41 | 74 | 52 | 78 | 30 | 57 | 0.97 € | 0.85 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 45 | 84 | 35 | 55 | 2.24 € | 0.40 rps |
| Cohere Command R ☁️ | 39 | 63 | 57 | 55 | 84 | 26 | 54 | 0.13 € | 2.47 rps |
| Qwen1.5 7B Chat f16 ⚠️ | 51 | 81 | 60 | 34 | 60 | 36 | 54 | 0.30 € | 3.62 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 60 | 75 | 33 | 53 | 2.31 € | 0.35 rps |
| Qwen1.5 14B Chat f16 ⚠️ | 44 | 58 | 51 | 49 | 84 | 17 | 51 | 0.38 € | 2.90 rps |
| Meta Llama 3 70B Instruct b8🦙 | 46 | 72 | 53 | 29 | 82 | 18 | 50 | 7.32 € | 0.22 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
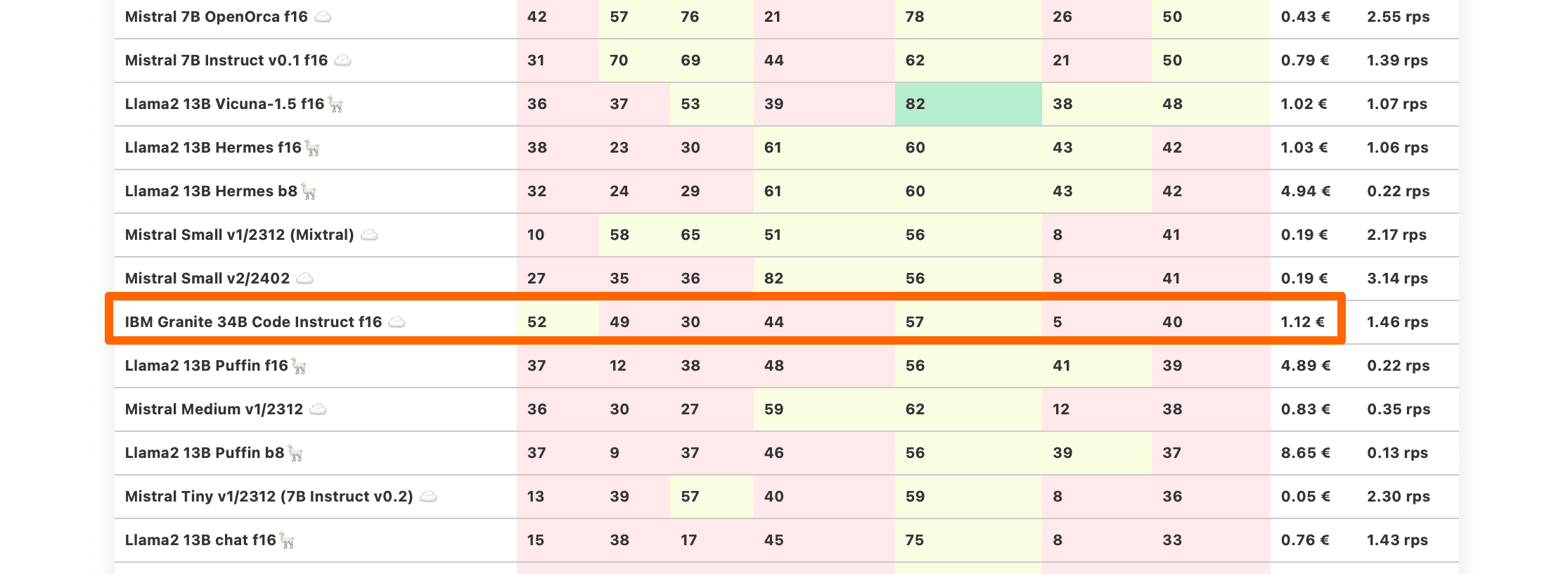
| IBM Granite 34B Code Instruct f16 ☁️ | 52 | 49 | 30 | 44 | 57 | 5 | 40 | 1.12 € | 1.46 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 48 | 56 | 41 | 39 | 4.89 € | 0.22 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 46 | 56 | 39 | 37 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 40 | 59 | 8 | 36 | 0.05 € | 2.30 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 45 | 75 | 8 | 33 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 45 | 75 | 6 | 32 | 3.35 € | 0.33 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 42 | 50 | 20 | 31 | 0.59 € | 1.86 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Microsoft Phi 3 Mini 4K Instruct f16 ⚠️ | 36 | 24 | 26 | 17 | 50 | 8 | 27 | 0.95 € | 1.15 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 3 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
The benchmark categories in detail
Here's exactly what we're looking at with the different categories of LLM Leaderboards
-
How well can the model work with large documents and knowledge bases?
-
How well does the model support work with product catalogs and marketplaces?
-
Can the model easily interact with external APIs, services and plugins?
-
How well can the model support marketing activities, e.g. brainstorming, idea generation and text generation?
-
How well can the model reason and draw conclusions in a given context?
-
Can the model generate code and help with programming?
-
The estimated cost of running the workload. For cloud-based models, we calculate the cost according to the pricing. For on-premises models, we estimate the cost based on GPU requirements for each model, GPU rental cost, model speed, and operational overhead.
-
The "Speed" column indicates the estimated speed of the model in requests per second (without batching). The higher the speed, the better.
Google Gemini 1.5 - Pro and Flash
The recent Google IO announcement was all about AI and Gemini Pro. Although Google managed to forget about Gemini Ultra (it was supposed to come out early this year), they did update a few models.
Gemini Pro 1.5 0514: Updated capabilities
Gemini Pro 1.5 0514 trades off some document comprehension capabilities in favour of better reasoning. It comes out as a slightly better version than the previous Gemini Pro version.
In our experience it was also a bit buggy at this point. We’ve encountered a bunch of server errors and even managed to get “HARM_CATEGORY_DANGEROUS_CONTENT” flag on one of the business benchmarks.
Excellent "Integrate" skills
Gemini Pro 1.5 scored a perfect "Integrate" score, where we measure LLM's ability to reliably follow instructions and work with external systems, plugins and data formats.
Gemini 1.5 Flash as an interesting alternative to GPT-3.5
Gemini 1.5 Flash is an interesting new addition to the family. It works well in document tasks and has decent reasoning capability. Combine that with a very low price, and you get a good alternative to GPT-3.5.
Just note Google Gemini's peculiar pricing model - they don't charge text by tokens, but by billable symbols(Unicode code points minus spaces). We have seen several developers and even SaaS systems make mistakes when estimating costs.

GPT-4o - Clearly in the lead, but with a caveat
GPT-4o looks perfect at first glance. It is faster and cheaper than GPT-4 turbo. It also has 128K context, scores higher, has native multi-modality and understands languages better.
Under the hood it has a new tokeniser with a bigger dictionary. It leads to reduced token counts.

Overall the model scores didn’t jump much higher, because we are already operating at the limit of the Trustbit LLM Benchmark. There is just one gotcha. Our “Reason” category (ability of models to handle complex logical and reasoning tasks) was made inherently difficult. GPT-4o managed to increase score from 62 (GPT-4 Turbo v3/1106-preview) to 75.
What is the caveat?
You see, OpenAI seems to operate in cycles. They switch between: “let’s make a better model” and “let’s make a cheaper model without sacrificing quality too much”.
While the LLM Benchmarks don’t catch it, it feels like the GPT-4o model belongs to the cost reduction models. It works amazingly well on small prompts, however other benchmarks demonstrate that it is not as good in dealing with larger contexts, like the other GPT-4 models. It also feels lacking in reasoning, even though current benchmarks are not capable of catching this regression.
💡 For the time being GPT-4 Turbo v5/2024-04-09 is our recommended go-to model.
Qwen 1.5 Chat
Highly demanded benchmark
Due to the high demand and good ratings in the LMSYS Arena, we decided to benchmark some flavours of Alibaba Cloud's Qwen Chat model.
Evaluation of Qwen 1.5 32B Chat
Qwen 1.5 32B Chat is quite good. It is within the range of GPT-3.5 models and Gemini Pro 1.0. It comes with a non-standard license, though.

We have also tested Qwen 1.5 7B and 14B - they are quite good for their relative size. Nothing peculiar, just a decent performance.

The license of Qwen1.5 Chat is a Chinese equivalent of Llama 3: you can use it freely for commercial purposes, if you have less than 100M MAU. This might make model adoption tricky in the USA and EU.
IBM Granite 34B Code Instruct
That is the only peculiar thing about their models, though. While the previous versions of IBM Granite models were available only within the IBM Cloud, the model under test was published directly to Hugging Face.
However, that is the only special thing about their models. While the previous versions of the IBM Granite models were only available within the IBM Cloud, the tested model was published directly on Hugging Face.
Long story short, IBM Granite 34B Code Instruct has a decent code capability (for a 7B model) and bad results in pretty much everything else. If you need a local coding model at a fraction of compute cost, just pick Llama3 or one of its derivatives.

Trustbit LLM Benchmarks Archive
Interested in the benchmarks of the past months? You can find all the links on our LLM Benchmarks overview page!