Benchmarks for ChatGPT and Co
February 2024

The highlights of the month:
Improvements to ChatGPT-4
Performance comparisons for the Mistral API and the Anthropic Claude models
First work on enterprise AI benchmarks
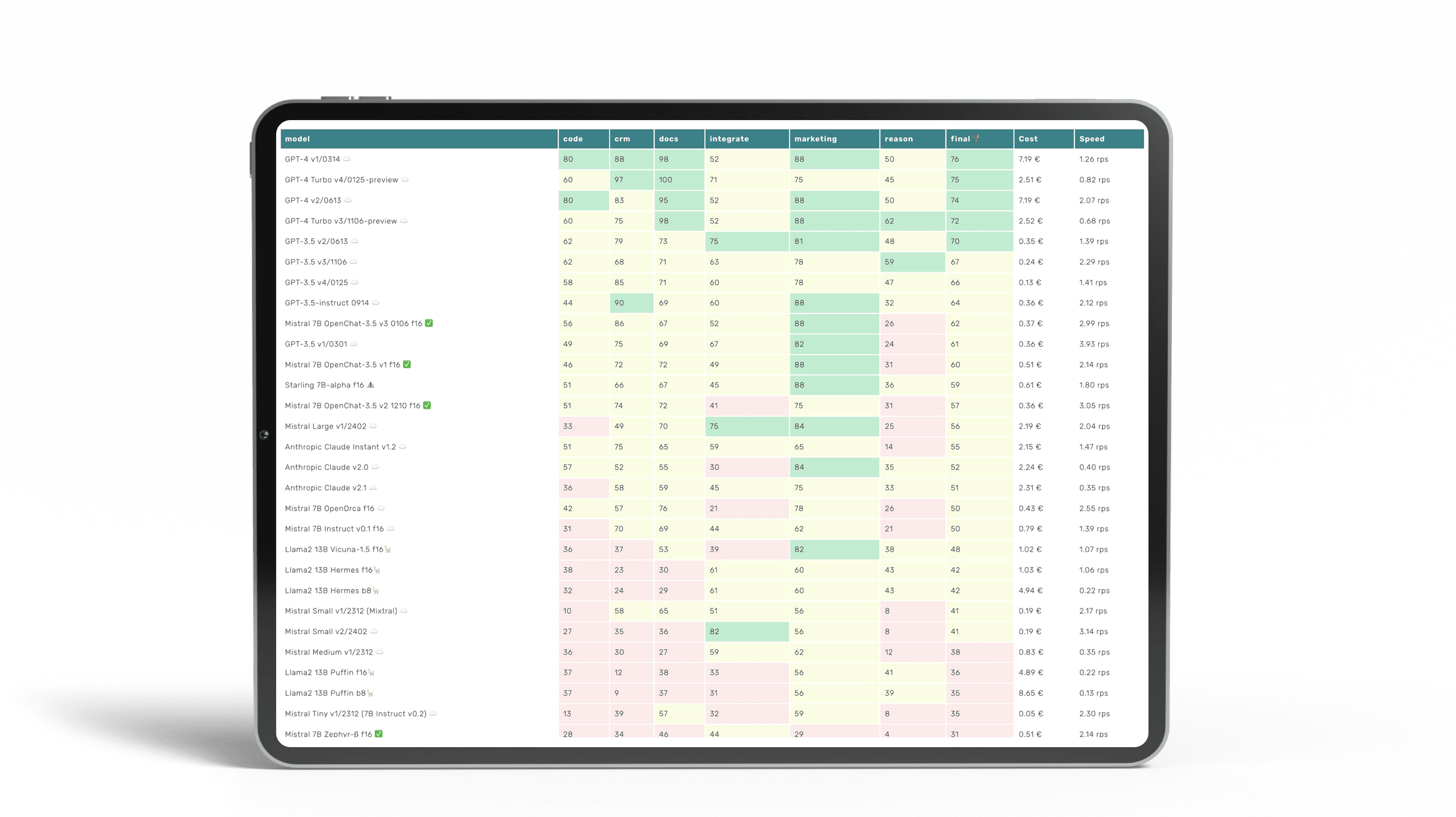
LLM Benchmarks | February 2024
The Trustbit benchmarks evaluate the models in terms of their suitability for digital product development. The higher the score, the better.
☁️ - Cloud models with proprietary license
✅ - Open source models that can be run locally without restrictions
🦙 - Local models with Llama license
Here is an updated report on the performance of LLM models in enterprise-specific workloads.
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
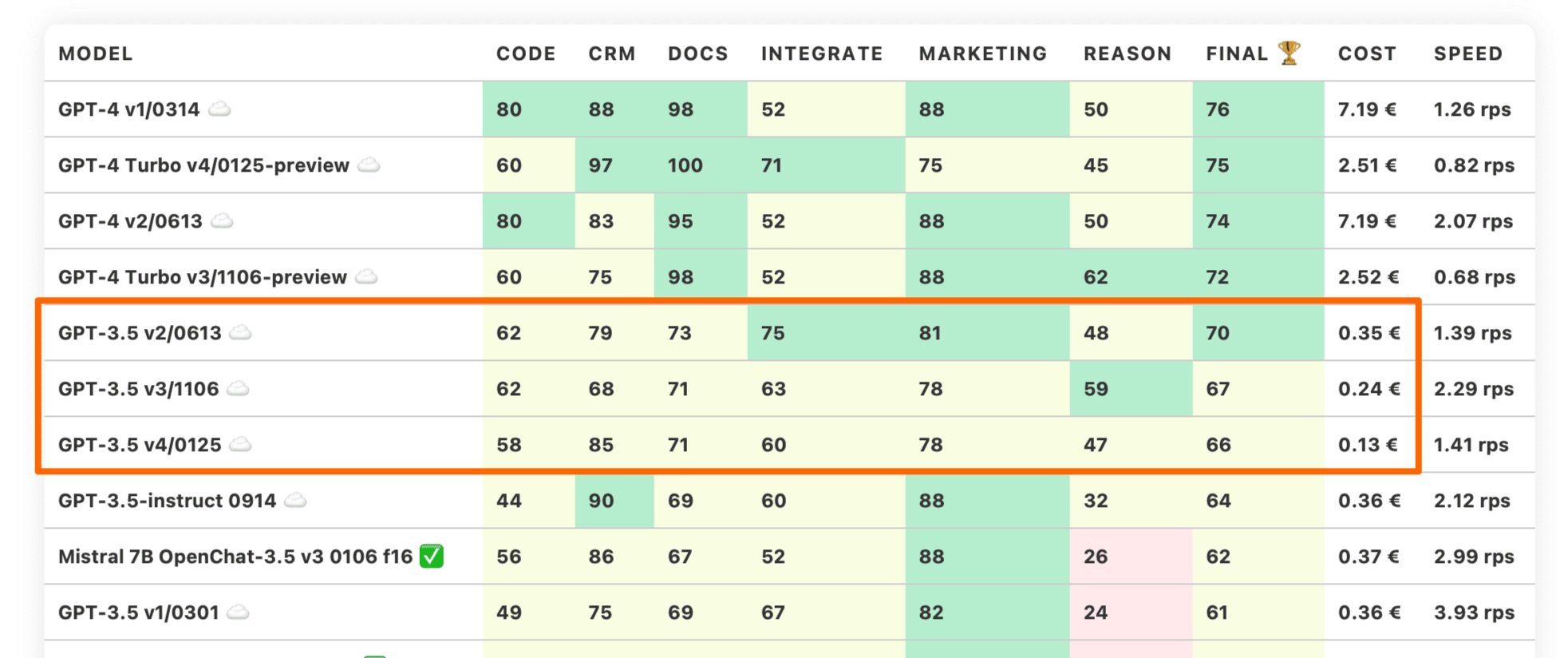
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 45 | 88 | 36 | 59 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 30 | 84 | 35 | 52 | 2.24 € | 0.40 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 45 | 75 | 33 | 51 | 2.31 € | 0.35 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 33 | 56 | 41 | 36 | 4.89 € | 0.22 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 31 | 56 | 39 | 35 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 32 | 59 | 8 | 35 | 0.05 € | 2.30 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 30 | 75 | 8 | 30 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 30 | 75 | 6 | 30 | 3.35 € | 0.33 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 27 | 50 | 20 | 28 | 0.59 € | 1.86 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 2 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
The benchmark categories in detail
Here's exactly what we're looking at with the different categories of LLM Leaderboards
-
How well can the model work with large documents and knowledge bases?
-
How well does the model support work with product catalogs and marketplaces?
-
Can the model easily interact with external APIs, services and plugins?
-
How well can the model support marketing activities, e.g. brainstorming, idea generation and text generation?
-
How well can the model reason and draw conclusions in a given context?
-
Can the model generate code and help with programming?
-
The estimated cost of running the workload. For cloud-based models, we calculate the cost according to the pricing. For on-premises models, we estimate the cost based on GPU requirements for each model, GPU rental cost, model speed, and operational overhead.
-
The "Speed" column indicates the estimated speed of the model in requests per second (without batching). The higher the speed, the better.
Improvements in Chat-GPT-4 - new recommendations
The latest update in the ChatGPT-v4 series finally breaks the trend of releasing cheaper models with lower accuracy. In our benchmarks, the GPT-4 0125 (or v4) finally beats the GPT-4 0613 (or v2) model.
This model also contains the latest training data (up to December 2023) and runs at a fraction of the cost of the v1 and v2 models, making the GPT-4 Turbo v4/0125-preview a new safe standard model that we can recommend.

The trend for GPT 3.5 models continues to follow the same pattern. New models are becoming cheaper and less powerful.
Mistral and Claude API - Verbosity Problem
This benchmark finally includes benchmarks for the Mistral AI and Anthropic Claude models:
Anthropic Claude Instant v1.2
Smaller LLM from Anthropic - it's anthropic.claude-instant-v1 on AWS Bedrock.
Anthropic Claude v2.1 and v2.1
Larger Anthropic LLMs that have introduced large context sizes - anthropic.claude-v2 series on AWS Bedrock.
Mistral Large Model
Recently released LLM from Mistral, which is positioned between GPT4 and GPT3.5 in internal benchmarks. It is mistral-large-2402 on La Plateforme.
Mistral Medium
Another proprietary model from Mistral, roughly comparable to Llama 70B, according to Miqu-Leak. We are testing mistral-medium-2312.
Mistral Small
This model was a very popular Mixtral 8x7B, but the second version does not say whether this is still the case. We test both versions: mistral-small-2402 and mistral-small-2312.
Mistral Tiny
This model corresponds to Mistral 7B Instruct v0.2 or mistral-tiny-2312 on Mistral AI.
All of these models can be good for creating content and chatting with people. However, that is not the point of our benchmark. We rank the models according to their ability to provide accurate answers in tasks such as information retrieval, document ranking or classification.
All these models are too wordy for that. Nor do they follow instructions precisely. Even local small series of Mistral 7B are better at this. ChatGPT-4 remains at the top. It seems that OpenAI understands the needs of enterprise customers better than the rest.

OUR CONCLUSION
If you need LLMs for chatbots and marketing purposes and are okay with some instructions being ignored, the Mistral AI and Anthropic models might be worth a closer look. Otherwise, we suggest to defer them for a while.
We introduce
Enterprise AI Leaderboard
We have been tracking the performance of LLM models for many months, this is our eighth report.
This process has helped us to gain first-hand experience in dealing with several different models at the same time. Unlike the usual academic benchmarks, we have been sourcing data from the real-world projects and enterprise tasks.
⭐️ New: LLM benchmarks from patronus ai
By the way, we are no longer alone in this area. Another company has recently started working on a similar set of enterprise benchmarks. We invite you to take a look at the Enterprise Scenarios Leaderboard on Hugging Face by PatronusAI.
That's all good, but it's time to address the real elephant in the room. The truth is:
Large language models are just an implementation detail.
Yes, it is true that a lot depends on their performance and capabilities. This is why, for example, in the short term we generally recommend GPT-4 Turbo v4/0125-preview as a model to start with.
However, we ultimately believe that the major language models are replaceable and interchangeable. In fact, the entire LLM ranking was started because of a recurring customer question: "When can I replace ChatGPT-4 with a local model in my projects?"
If you look at the "Request For Startups" from YCombinator, one specific request focuses on the exact topic of replacement: small fine-tuned models as an alternative to huge generic models. YCombinator helped to incubate companies like Stripe, Dropbox, Twitch and Cruise. They know a thing or two when it comes to market trends and industry trends.
Giant generic models with many parameters are very impressive. But they are also very costly and often come with latency and privacy challenges. Fortunately, smaller open-source models such as Llama2 and Mistral have already shown that, when fine-tuned with suitable data, they can deliver comparable results at a fraction of the cost.
To push the concept even further, we believe that the local large models will be the way to improve the overall accuracy of the system beyond the capabilities of ChatGPT, while significantly reducing operational costs.
note
Per-system customization makes it possible to design systems that learn and adapt to the specifics of each individual company. We're not even talking about advanced topics like fine-tuning (this requires a lot of high-quality data). Even a simple customization of call and context based on statistics can work wonders.
Since individual LLMs are an implementation detail, what should be the metric to measure the state of the art when applying AI to enterprise workloads?
Here is a hint in the form of some questions we are asked:
Which RAG architecture is best for legal workloads?
Which vector database should we use to build an internal support bot?
What is the best approach to automatically handle company questionnaires with 1000 questions in B2B sales?
The metric should target and compare complete enterprise and business AI solutions. End-to-end.
Anybody can claim 99% accuracy on RAG tasks. We want to independently verify it, build a better intuition about different architectures and ultimately allow our customers to make more informed decisions.
t will take time and effort to build a full Enterprise AI Leaderboard. We are starting with the foundational capability - ability of AI system to find relevant information within the business-specific documentation. This is the foundational block of RAG systems.
Here is an example: We took a public annual report from the Christian Dior Group. Then we asked the AI system 10 specific questions about this report. For example:
What was the company's turnover in 2022?
How much liquidity did the company have at the end of 2021?
What was the gross margin in 2023?
How many employees did the company have in 2022?
As you can see, each question has only one correct answer. No calculations or advanced reasoning are required.
How well do you think different systems would deal with these specific issues?
Not so good!
We have tested some common systems to get you started:
ChatGPT-4
OpenAI Assistant API with document retrieval and gpt-4-0125 model
Two popular services for asking questions about a specific PDF: ChatPDF and AskYourPDF.
Each test involved uploading the annual report and asking the question with a very specific instruction:
PROMT
Answer with a floating point number in actual currency, for example "1.234 million", use the decimal point and no thousands separators. you can think through the answer, but the last line should be in this format "Answer = Number Unit". Answer with "Answer = None" if no information is available.
This instruction was important because:
we would like to encourage models to use the chain-thought-of-process (CoT) if this increases accuracy
we still need the number to be parseable in a specific locale, hence the strict requirement on using decimal comma and no thousand separators (just like in the original report).
Obviously, RAG-systems, being end-to-end solutions, would already have CoT baked into the pipelines underneath the covers. However, when we added instruction into the overall request prompt, overall accuracy still increased.
Below are the final scores of multiple RAG systems in a single test. We gave each system 1 point for a correct and parseable answer. 0.5 points for an answer that pulled the right bit of information but made an order of magnitude error.
| Question | Answer | ChatGPT-4 | gpt-4-0125 RAG | ChatPDF | Ask Your PDF |
|---|---|---|---|---|---|
| How much liquidity did this company have at hand at the end of 2021? | 8.122 million | 7.388 million euro | 7.918 million | 10.667 million euros | INVALID |
| How much liquidity did this company have at hand at the end of 2022? | 7.588 million | 7.388 billion euros | 7.388 million | 11.2 billion euros | 7588 million euros |
| How many employees did the company have at the end of 2022? | 196006 | 196,006 | 196,006 | 196006 | INVALID |
| How much were total lease liabilities of the company by the end of 2021? | 14.275 million | 14.275 million | 14,275 million | 14,275 | 14.275 million euros |
| What amount was recorded for the repayment of lease liabilities in 2022? | 2.453 million | 2.453 million | 2,711 million | 2.711 million | 2.711 million euros |
| What was the company's net revenue in 2021? | 64.215 million | 64.215 million | 64.215 million | 64.215 million euros | 64,215 million euros |
| What was the company's net revenue in 2022? | 79.184 million | 79.184 million | 79184 million euros | EUR 79.184 million | EUR 79.184 million |
| What was the company's net revenue in 2023? | None | None | None | None | INVALID |
| What was the total shareholder equity at the end of 2022? | 54.314 million | 54.3 billion | 54.314 million | 54.314 billion euros | INVALID |
| What was the company's gross margin for the year 2021? | 43.860 million | 43.860 million euros | 43.860 million | 43.860 million euros | 43.860 million euros |
| SCORE | 100 | 70 | 60 | 55 | 40 |
So far, OpenAI's RAG systems are the best on the market for the task at hand. However, we do not expect this to remain the case for long.
Specialized solutions are capable of achieving higher scores, even without the use of cutting-edge LLMs. We know this for a fact, because we have built such systems. One of them even includes the use of Mistral-7B-OpenChat-3.5 to extract information from tens of thousands of PDF documents.
As we extend and enrich this enterprise AI benchmark with more cases and solutions, it is expected that ChatGPT will eventually be dethroned.
Trustbit LLM Benchmarks Archive

Interested in the benchmarks of the past months? You can find all the links on our LLM Benchmarks overview page!