December 2023
Benchmarks for ChatGPT & Co:


The Christmas vacations are coming up, so we have prepared something special this time!
New multilingual Trustbit LLM benchmark
New models: Starling 7B, Notus 7B and Microsoft Orca
All local models were recalculated with active Beam Search.
Multilingual Trustbit LLM Benchmarks
Have you heard that ChatGPT works better with the English language and may be less efficient with other languages?
This is well known among users. It affects not only ChatGPT, but also other major language models. The main cause is that the training dataset contains much more English than other languages.
The consequence is that ChatGPT can suddenly become less efficient when it has to deal with texts in other languages. The results will be less accurate and the rate of hallucinations will increase.
This could come as an unpleasant surprise for international companies looking to develop AI capabilities for multiple languages.
The central question is therefore:
How well can ChatGPT speak the languages of my company?
To help our customers better navigate the multilingual AI space, Trustbit has created the multilingual benchmark for large language models.
This first publication compares the performance of LLM models in 16 different languages, ranging from English and German to Ukrainian and Swedish.
This benchmark was created with the help of linguistic experts and our Trustbit colleagues (they come from a diversity of countries and backgrounds). Each language was contributed by a native speaker.
Trustbit's Multilingual LLM Benchmark does not go as deeply into the capabilities of the models as our product benchmark. It focuses on basic linguistic capabilities:
- Understanding and executing instructions in a specific language.
- understanding words in a language, reason about them and infer meaning
This is already sufficient to compare the performance of different models in one language or to find out which languages are well supported by a model of your choice.
An accuracy of 100 means that the model was able to carry out all instructions. An accuracy of 50 means that it did half of the tasks incorrectly.
The abbreviations in the table stand for:
BAK: Bashkir, CHV: Chuvash, DEU: German, ENG: English, FRA: French, HUN: Hungarian, KPV: Komi-Zyrian, KRC: Karachay-Balkar, KUM: Kumyk, MHR: Eastern Mari, POL: Polish, POR: Portuguese, RUS: Russian, SAH: Sakha, SWE: Swedish, TAT: Tatian, UDM: Udmurt, UKR: Ukrainian

Conclusio
As you can see, of the 16 languages and 25 models evaluated, only ChatGPT is truly fluent in multiple languages. The other model-language combinations are less supported.
My language is not supported by LLMs. What now?
If some languages are not well supported by a generative AI model of your choice, there are still several options to use AI effectively.
As part of Trustbit research and development, we work with low-resource languages (languages spoken by 0.01% of the world's population or even less). Some of this expertise can also be transferred as insights for AI-driven business systems:
1. use automated translation to convert prompts to English, and then convert results back. It is easier to train great translation model, than it is to create a good foundational model.
2. send both the text of the translation and the original text to LLMs on request.
3. non-English languages can use more tokens per request. This leads to smaller effective context windows and more expensive requests. Therefore, pay attention to the token usage in your requests.
4. make sure you prefix the request with “you are a native speaker in language X” to the prompt, ensuring that LLM switches to the right context from the start.
5. use Retrieval Augmented Generation (RAG) to include relevant domain-specific snippet information in the AI queries. Use language-specific embeddings for this. Enrich the context with GPT-generated hints, even if you perform the final inference on local models.
6. when building a language-based interaction, try to use multi-modal models (e.g. map audio requests directly to English via the shared vector space). This reduces the number of semantic "hops" that affect accuracy.
How do you write a bad multilingual benchmark?
A good benchmark requires effort, collaboration with linguists and GPU time. With all these investments, we realized that it is trivial to write a benchmark where even ChatGPT 4 will fail.
Here are two simple questions in English:

The first answer is obviously wrong because there are three rhyming words: "mouse", "house" and "spouse". The second answer is wrong because the stress is on the third syllable, not the second.
Does this mean that ChatGPT 4 handles English poorly? No, it just means that this is a poor benchmark to assess linguistic ability. The tasks of rhyming or stressing syllables are intuitive for people who learn by listening and speaking. However, text-based large language models (such as ChatGPT or Llama) only learn by reading and writing.
In addition, this benchmark is not useful because it prevents meaningful comparisons of models across different languages. After all, rhyming occurs differently in different languages. Tonal languages, such as Chinese, can integrate tonal patterns (i.e. the changes in pitch during speech) into rhyme schemes. The particular characteristics of each language influence how rhyme and rhythm are formed in their respective linguistic structures.
When creating the Multilingual Trustbit LLM benchmark, we tried to take these and many other linguistic subtleties into account.
When developing the Multilingual Trustbit LLM benchmark, we tried to take these and many other linguistic subtleties into account.
New models
We have new models in the benchmark:
Starling 7B-alpha - further fine-tuning based on OpenChat 3.5
Mistral 7B Notus-v1 - another promising Mistral fine-tuning (LoRA)
Microsoft Orca 2 13B and 7B - a new basic model from Microsoft.
These models are included in both the classic Trustbit LLM benchmark and the multilingual benchmark.
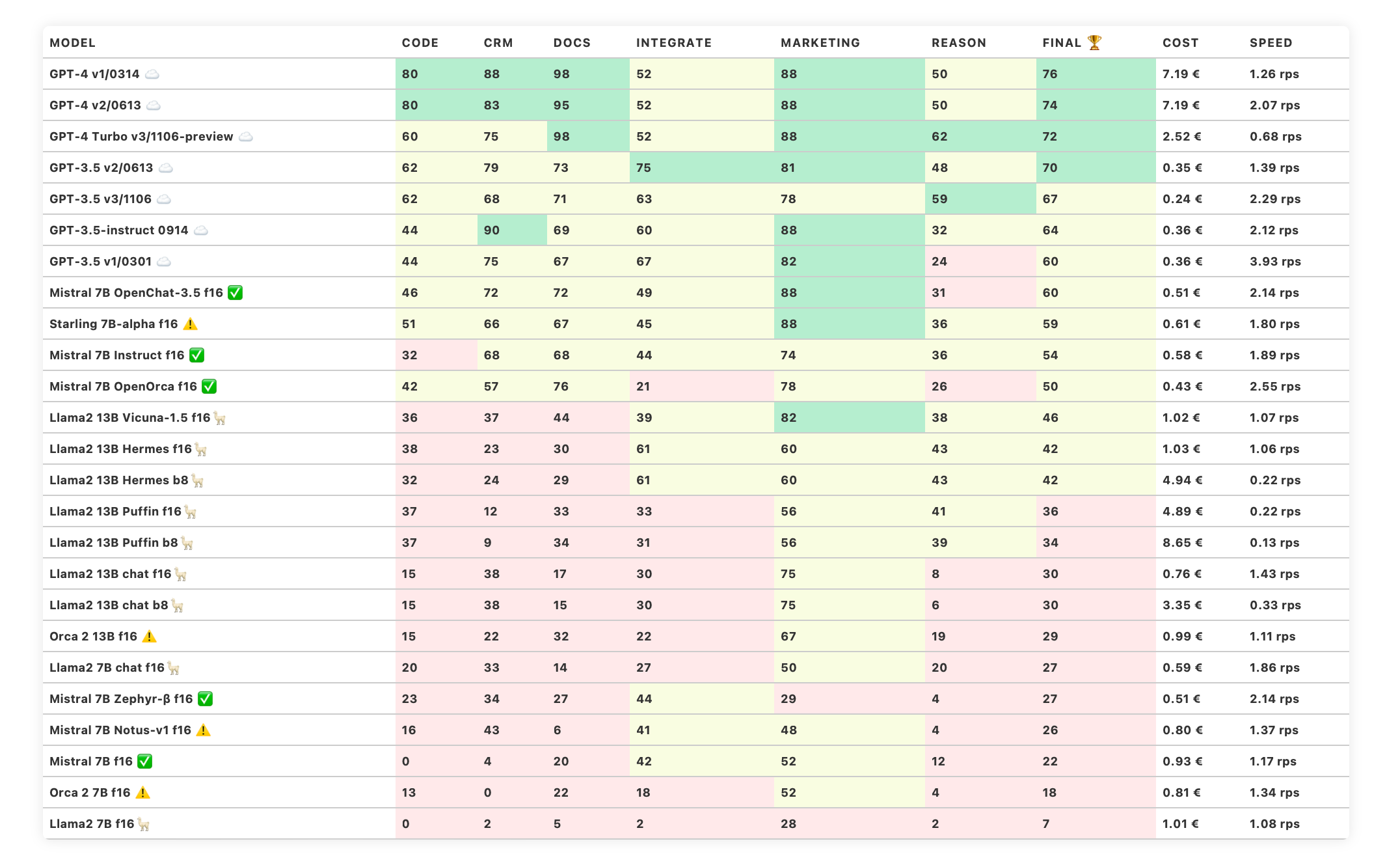
The benchmark categories in detail
-
How well can the model work with large documents and knowledge bases?
-
How well does the model support work with product catalogs and marketplaces?
-
Can the model easily interact with external APIs, services and plugins?
-
How well can the model support marketing activities, e.g. brainstorming, idea generation and text generation?
-
How well can the model reason and draw conclusions in a given context?
-
Can the model generate code and help with programming?
-
The estimated cost of running the workload. For cloud-based models, we calculate the cost according to the pricing. For on-premises models, we estimate the cost based on GPU requirements for each model, GPU rental cost, model speed, and operational overhead.
-
The "Speed" column indicates the estimated speed of the model in requests per second (without batching). The higher the speed, the better.
Statistics
Did you know that we had to perform 12,150 chat completions (prompts) to create these two tables? Or even more if you consider Beam Search optimization, which is now enabled for all available models.
Trustbit LLM Benchmarks Archive

Interested in the benchmarks of the past months? You can find all the links on our LLM Benchmarks overview page!