Benchmarks for ChatGPT and Co
April 2024


The highlights of the month:
Gemini Pro 1.5 from Google - Improvement of Pro 1.0, now available in the EU
Command-R and Command-R Plus from Cohere - mediocre results
New GPT-4 Turbo - OpenAI has done it again!
Llama 3: 70B is fine, but 8B is really promising
Long-term trends
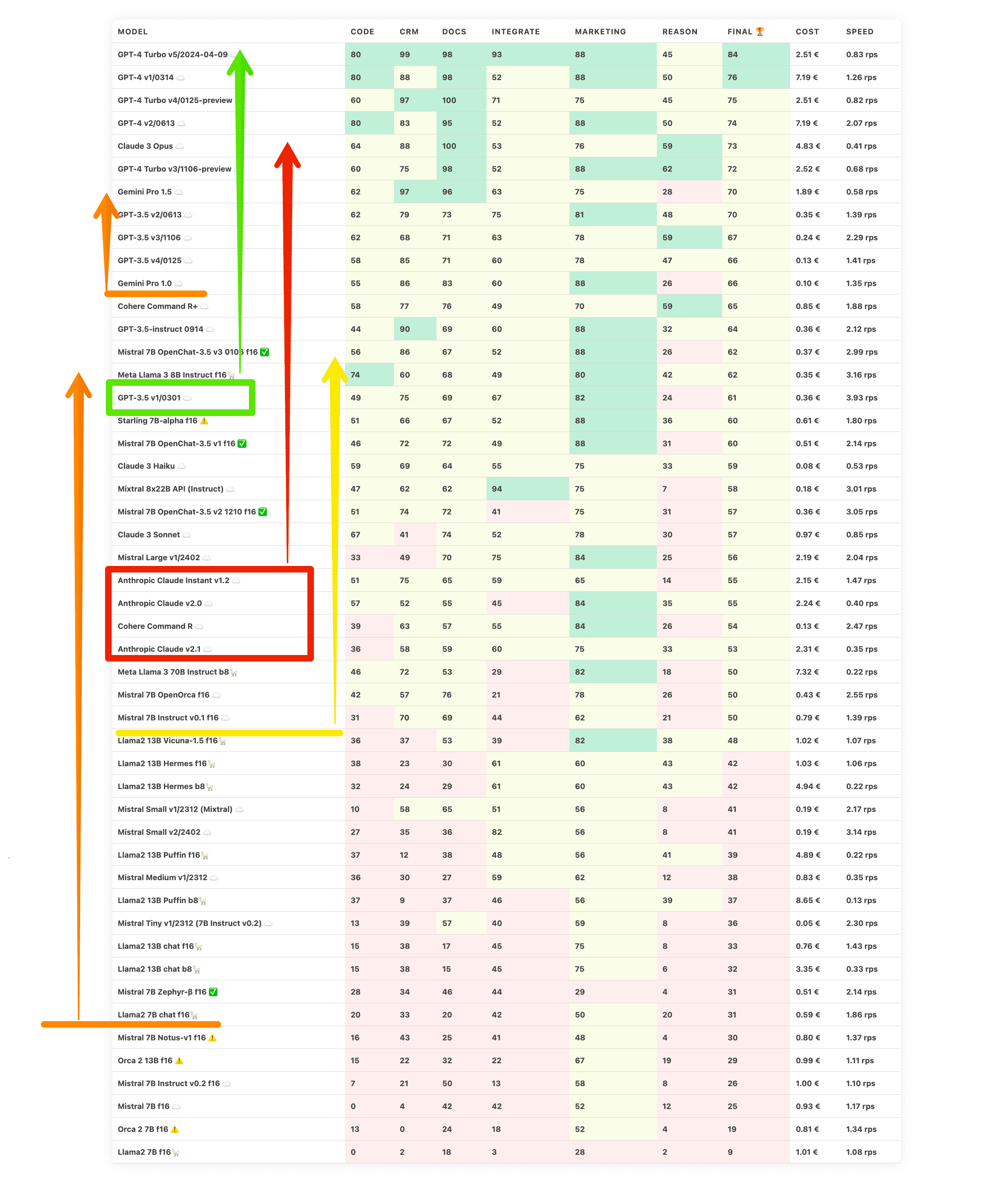
LLM Benchmarks | April 2024
The Trustbit benchmarks evaluate the models in terms of their suitability for digital product development. The higher the score, the better.
☁️ - Cloud models with proprietary license
✅ - Open source models that can be run locally without restrictions
🦙 - Local models with Llama license
| model | code | crm | docs | integrate | marketing | reason | final 🏆 | Cost | Speed |
|---|---|---|---|---|---|---|---|---|---|
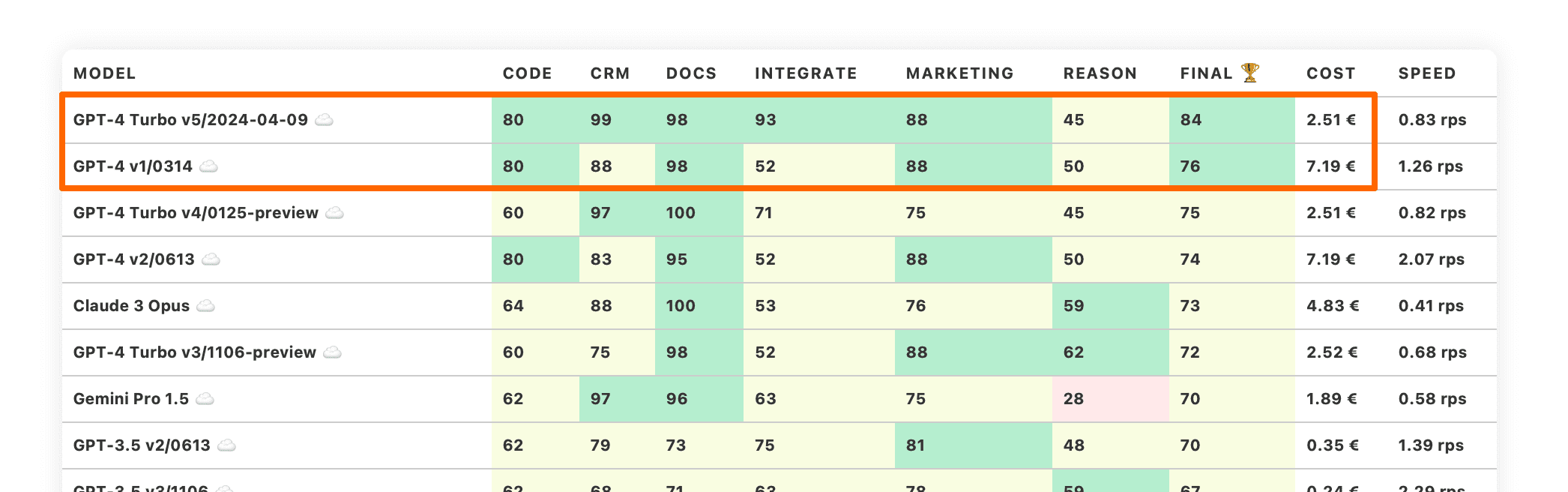
| GPT-4 Turbo v5/2024-04-09 ☁️ | 80 | 99 | 98 | 93 | 88 | 45 | 84 | 2.51 € | 0.83 rps |
| GPT-4 v1/0314 ☁️ | 80 | 88 | 98 | 52 | 88 | 50 | 76 | 7.19 € | 1.26 rps |
| GPT-4 Turbo v4/0125-preview ☁️ | 60 | 97 | 100 | 71 | 75 | 45 | 75 | 2.51 € | 0.82 rps |
| GPT-4 v2/0613 ☁️ | 80 | 83 | 95 | 52 | 88 | 50 | 74 | 7.19 € | 2.07 rps |
| Claude 3 Opus ☁️ | 64 | 88 | 100 | 53 | 76 | 59 | 73 | 4.83 € | 0.41 rps |
| GPT-4 Turbo v3/1106-preview ☁️ | 60 | 75 | 98 | 52 | 88 | 62 | 72 | 2.52 € | 0.68 rps |
| Gemini Pro 1.5 ☁️ | 62 | 97 | 96 | 63 | 75 | 28 | 70 | 1.89 € | 0.58 rps |
| GPT-3.5 v2/0613 ☁️ | 62 | 79 | 73 | 75 | 81 | 48 | 70 | 0.35 € | 1.39 rps |
| GPT-3.5 v3/1106 ☁️ | 62 | 68 | 71 | 63 | 78 | 59 | 67 | 0.24 € | 2.29 rps |
| GPT-3.5 v4/0125 ☁️ | 58 | 85 | 71 | 60 | 78 | 47 | 66 | 0.13 € | 1.41 rps |
| Gemini Pro 1.0 ☁️ | 55 | 86 | 83 | 60 | 88 | 26 | 66 | 0.10 € | 1.35 rps |
| Cohere Command R+ ☁️ | 58 | 77 | 76 | 49 | 70 | 59 | 65 | 0.85 € | 1.88 rps |
| GPT-3.5-instruct 0914 ☁️ | 44 | 90 | 69 | 60 | 88 | 32 | 64 | 0.36 € | 2.12 rps |
| Mistral 7B OpenChat-3.5 v3 0106 f16 ✅ | 56 | 86 | 67 | 52 | 88 | 26 | 62 | 0.37 € | 2.99 rps |
| Meta Llama 3 8B Instruct f16🦙 | 74 | 60 | 68 | 49 | 80 | 42 | 62 | 0.35 € | 3.16 rps |
| GPT-3.5 v1/0301 ☁️ | 49 | 75 | 69 | 67 | 82 | 24 | 61 | 0.36 € | 3.93 rps |
| Starling 7B-alpha f16 ⚠️ | 51 | 66 | 67 | 52 | 88 | 36 | 60 | 0.61 € | 1.80 rps |
| Mistral 7B OpenChat-3.5 v1 f16 ✅ | 46 | 72 | 72 | 49 | 88 | 31 | 60 | 0.51 € | 2.14 rps |
| Claude 3 Haiku ☁️ | 59 | 69 | 64 | 55 | 75 | 33 | 59 | 0.08 € | 0.53 rps |
| Mixtral 8x22B API (Instruct) ☁️ | 47 | 62 | 62 | 94 | 75 | 7 | 58 | 0.18 € | 3.01 rps |
| Mistral 7B OpenChat-3.5 v2 1210 f16 ✅ | 51 | 74 | 72 | 41 | 75 | 31 | 57 | 0.36 € | 3.05 rps |
| Claude 3 Sonnet ☁️ | 67 | 41 | 74 | 52 | 78 | 30 | 57 | 0.97 € | 0.85 rps |
| Mistral Large v1/2402 ☁️ | 33 | 49 | 70 | 75 | 84 | 25 | 56 | 2.19 € | 2.04 rps |
| Anthropic Claude Instant v1.2 ☁️ | 51 | 75 | 65 | 59 | 65 | 14 | 55 | 2.15 € | 1.47 rps |
| Anthropic Claude v2.0 ☁️ | 57 | 52 | 55 | 45 | 84 | 35 | 55 | 2.24 € | 0.40 rps |
| Cohere Command R ☁️ | 39 | 63 | 57 | 55 | 84 | 26 | 54 | 0.13 € | 2.47 rps |
| Anthropic Claude v2.1 ☁️ | 36 | 58 | 59 | 60 | 75 | 33 | 53 | 2.31 € | 0.35 rps |
| Meta Llama 3 70B Instruct b8🦙 | 46 | 72 | 53 | 29 | 82 | 18 | 50 | 7.32 € | 0.22 rps |
| Mistral 7B OpenOrca f16 ☁️ | 42 | 57 | 76 | 21 | 78 | 26 | 50 | 0.43 € | 2.55 rps |
| Mistral 7B Instruct v0.1 f16 ☁️ | 31 | 70 | 69 | 44 | 62 | 21 | 50 | 0.79 € | 1.39 rps |
| Llama2 13B Vicuna-1.5 f16🦙 | 36 | 37 | 53 | 39 | 82 | 38 | 48 | 1.02 € | 1.07 rps |
| Llama2 13B Hermes f16🦙 | 38 | 23 | 30 | 61 | 60 | 43 | 42 | 1.03 € | 1.06 rps |
| Llama2 13B Hermes b8🦙 | 32 | 24 | 29 | 61 | 60 | 43 | 42 | 4.94 € | 0.22 rps |
| Mistral Small v1/2312 (Mixtral) ☁️ | 10 | 58 | 65 | 51 | 56 | 8 | 41 | 0.19 € | 2.17 rps |
| Mistral Small v2/2402 ☁️ | 27 | 35 | 36 | 82 | 56 | 8 | 41 | 0.19 € | 3.14 rps |
| Llama2 13B Puffin f16🦙 | 37 | 12 | 38 | 48 | 56 | 41 | 39 | 4.89 € | 0.22 rps |
| Mistral Medium v1/2312 ☁️ | 36 | 30 | 27 | 59 | 62 | 12 | 38 | 0.83 € | 0.35 rps |
| Llama2 13B Puffin b8🦙 | 37 | 9 | 37 | 46 | 56 | 39 | 37 | 8.65 € | 0.13 rps |
| Mistral Tiny v1/2312 (7B Instruct v0.2) ☁️ | 13 | 39 | 57 | 40 | 59 | 8 | 36 | 0.05 € | 2.30 rps |
| Llama2 13B chat f16🦙 | 15 | 38 | 17 | 45 | 75 | 8 | 33 | 0.76 € | 1.43 rps |
| Llama2 13B chat b8🦙 | 15 | 38 | 15 | 45 | 75 | 6 | 32 | 3.35 € | 0.33 rps |
| Mistral 7B Zephyr-β f16 ✅ | 28 | 34 | 46 | 44 | 29 | 4 | 31 | 0.51 € | 2.14 rps |
| Llama2 7B chat f16🦙 | 20 | 33 | 20 | 42 | 50 | 20 | 31 | 0.59 € | 1.86 rps |
| Mistral 7B Notus-v1 f16 ⚠️ | 16 | 43 | 25 | 41 | 48 | 4 | 30 | 0.80 € | 1.37 rps |
| Orca 2 13B f16 ⚠️ | 15 | 22 | 32 | 22 | 67 | 19 | 29 | 0.99 € | 1.11 rps |
| Mistral 7B Instruct v0.2 f16 ☁️ | 7 | 21 | 50 | 13 | 58 | 8 | 26 | 1.00 € | 1.10 rps |
| Mistral 7B f16 ☁️ | 0 | 4 | 42 | 42 | 52 | 12 | 25 | 0.93 € | 1.17 rps |
| Orca 2 7B f16 ⚠️ | 13 | 0 | 24 | 18 | 52 | 4 | 19 | 0.81 € | 1.34 rps |
| Llama2 7B f16🦙 | 0 | 2 | 18 | 3 | 28 | 2 | 9 | 1.01 € | 1.08 rps |
The benchmark categories in detail
Here's exactly what we're looking at with the different categories of LLM Leaderboards
-
How well can the model work with large documents and knowledge bases?
-
How well does the model support work with product catalogs and marketplaces?
-
Can the model easily interact with external APIs, services and plugins?
-
How well can the model support marketing activities, e.g. brainstorming, idea generation and text generation?
-
How well can the model reason and draw conclusions in a given context?
-
Can the model generate code and help with programming?
-
The estimated cost of running the workload. For cloud-based models, we calculate the cost according to the pricing. For on-premises models, we estimate the cost based on GPU requirements for each model, GPU rental cost, model speed, and operational overhead.
-
The "Speed" column indicates the estimated speed of the model in requests per second (without batching). The higher the speed, the better.
Google Gemini Pro 1.5
In our March benchmarks, we tested Gemini Pro 1.0 from Google. The newer version Gemini 1.5 Pro shows significantly better performance. It almost reaches the performance of the GPT-4 Turbo.
This model performs particularly well on tasks related to working on documents and information. It also performs almost perfectly on CRM-related tasks. However, complex reasoning tasks are below the level of GPT-3.5.
Gemini Pro 1.5 is about 20 times more expensive than Pro 1.0 on our workloads, which is to be expected given the quality level of GPT-4.
Both models are now available in Google Vertex AI, finally making them usable for enterprise customers in the EU.

Command R models from Cohere
Cohere AI specializes in enterprise-oriented LLMs. They have the Command R family of models - LLMs designed for document-oriented tasks: "Command R" and "Command R Plus".
These models are available both as API SaaS and as downloadable models on Hugging Face. Downloadable models are published for non-commercial purposes.
The Command-R model is roughly comparable to the Anthropic Claude models of the first two generations, but significantly cheaper. Nevertheless, there are better models in this price category, such as Gemini Pro 1.0 and Claude 3 Haiku.
The Command R+ is a significantly better model with capabilities in the GPT-3.5 range, but at two to three times the price.

OpenAI reaches another milestone with new ChatGPT-4 Turbo
OpenAI has released the new GPT-4 Turbo model with the version number 2023-04-09. This is outstanding for two reasons.
First, OpenAI has finally used sensible version numbers. It only took one year of progress.
Second, this model beats all the other models on our LLM benchmarks. It takes the top place with a substantial gap to the second place.
This score jump comes from nearly perfect stores in CRM and Docs categories. Plus OpenAI has finally fixed the instruction following problem with few-shots, that was causing Integrate category to be so low.
GPT-4 Turbo 2023-04-09 is currently our default recommendation for the new LLM-driven projects that need the best performing LLM to get started.
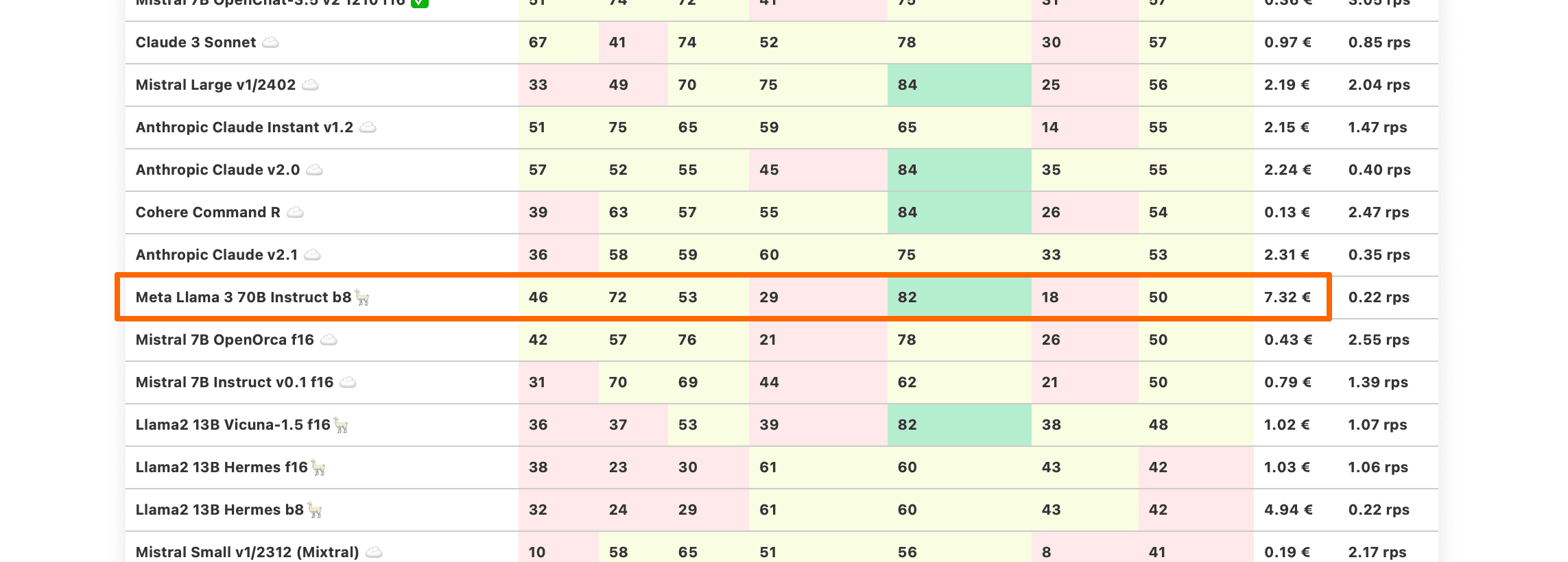
Llama 3 70B and 8B
Meta has just released new models in its third generation. We have tested instruct versions of 70B and 8B for the usability in LLM-driven products.
Llama 3 70B had a bumpy start - the upload to HuggingFace had bugs with tokens in chat template processing. Once these were fixed, the model started working better, on the level of old generations of Anthropic Claude v2.
Note that we tested the b8 quantized model to properly fit 2xA100 80GB SMX cards. There is a possibility that f16 might give slightly better results.
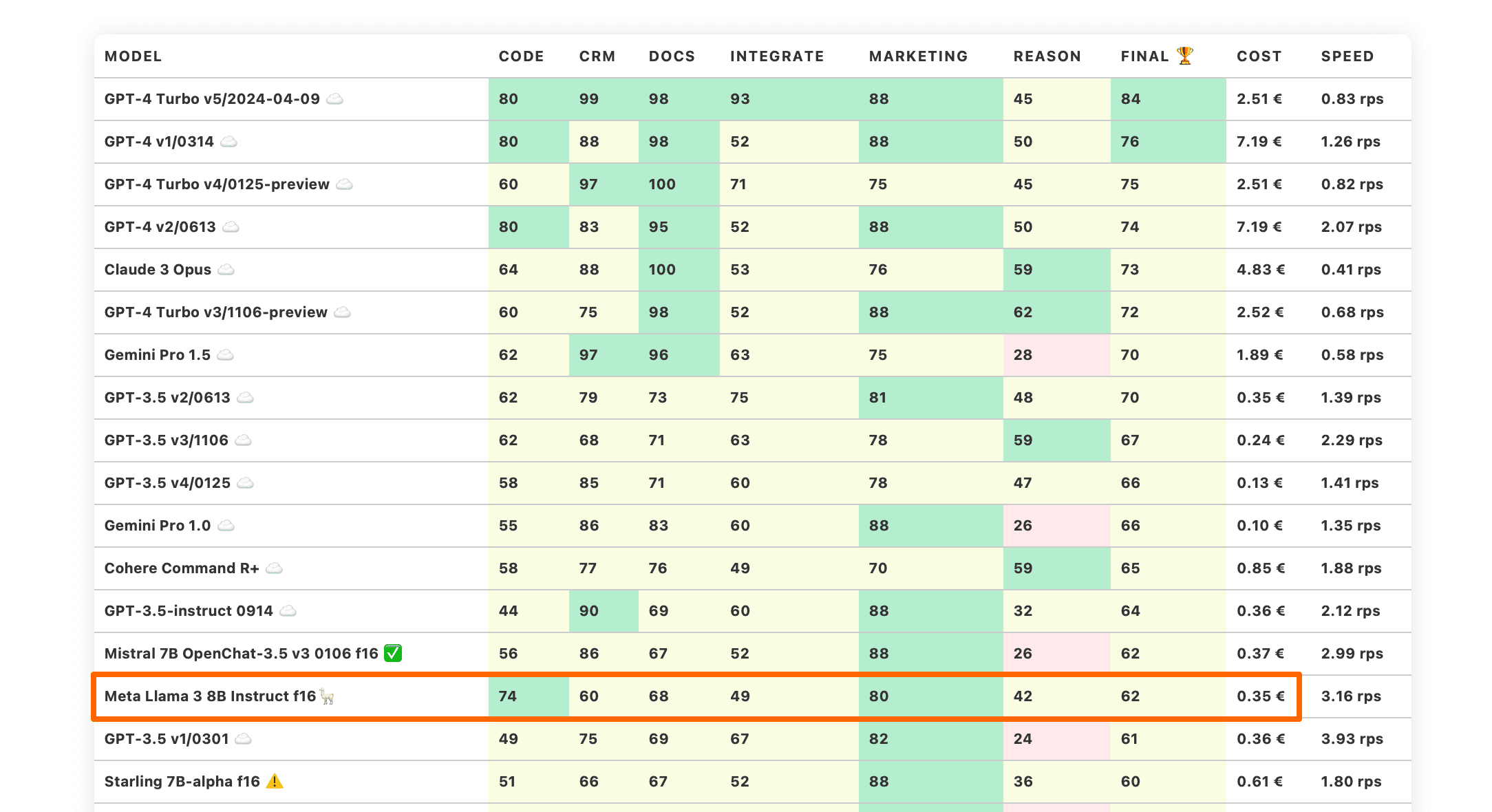
Llama 3 8B Instruct performed much better on the benchmarks, pushing forward state of the art that is made available by Meta. This model has surprisingly good overall scores and a good “Reason” capability. There is a strong chance that product-oriented fine-tune of Llama3 8B Instruct would be able to push this model to the TOP-10.
Long-term trends
Now let's look at the bigger picture: Where is the industry heading with all this?
More cost-effective & more powerful models
First of all, models are generally getting better and more affordable. This is the general trend that Sam Altman recently outlined in his interview: Which companies are being overrun by OpenAI?
Further long-term LLM trends
New functional capabilities of LLMs
LLMs gain new functional capabilities that are not even covered in this benchmark: Function calls, multimodality, data grounding. The latest version of LLM Under the Hood expands on this theme.
Experiments with new LLM architectures
Companies also get bold and try to experiment with new LLM architectures outside of the classical transformers architecture. Mixture of Experts was popularised by Mistral, although many believe that GPT also uses it. Recurrent Neural Networks also experience a comeback as a way to solve context size limitations. For example: RWKV Language Model, Recurrent Gemma from Google Deep Mind (Griffin architecture).
Powerful models with low computing power
What is interesting about these models - they show decent capabilities, while requiring substantially less compute. For instance, we got a report of 0.4B version of RWKV running on a low-end Android phone with a tolerable speed (CPU-only inference).
Where are we heading with all this?
Democratization of AI
Expect the models to continue to get better, cheaper and more powerful. Sam Altman calls this the "democratization of AI". This applies to both cloud models and locally available models.
If you are in the process of building an LLM-driven system, expect that by the time the system is delivered, the underlying LLM will be much more powerful. In fact, you can take this into account and build a long-term strategy around it.
Adaptable systems
You can do that, for example, by designing LLM-driven systems to be transparent, auditable and capable of continuously adapting to the changing context. There is some information on this topic in our new section on building AI assistants for business .

Trustbit LLM Benchmarks Archive
Interested in the benchmarks of the past months? You can find all the links on our LLM Benchmarks overview page!